안녕하세요, 커브입니다.
초여름의 기운이 조금씩 느껴지는 5월입니다. 이번 뉴스레터에서는 개발과 서비스 관리 현장에서 빠르게 확산되고 있는 AI 활용 흐름을 살펴봅니다.
AI 보안 도구와 정적 분석 도구는 어떻게 함께 활용될 수 있는지, 또 Jira Service Management는 AI를 통해 서비스 운영을 어떻게 더 빠르고 일관되게 만드는지 확인해 보세요.
|
|




출처:
작성자:
Nikos Drakos, Joe Mariano 외 2명
발행일: 2025년 10월 28일
Atlassian이 2025 Gartner® Magic Quadrant™ 협업 업무 관리(Collaborative Work Management) 부문에서 리더 기업으로 선정되었습니다.
이번 평가는 단순한 프로젝트 관리 도구를 넘어, 조직 전반의 업무 흐름과 협업 방식을 어떻게 연결하고 있는지에 대한 시장의 방향성을 보여줍니다.
가트너는 협업 업무 관리(CWM) 플랫폼을 업무 계획, 협업, 자동화, 문서 관리, 분석, AI 기반 지원 기능 등을 통합적으로 제공하는 플랫폼으로 정의하고 있습니다.
특히 최근 기업 환경에서는 업무 관리, 문서 협업, 커뮤니케이션, 지식 공유가 각각 분리된 도구로 운영되는 경우가 많으며, 이로 인해 업무 맥락 단절과 협업 비효율 문제가 지속적으로 발생하고 있습니다.
Atlassian은 이러한 흐름 속에서 Jira, Confluence, Loom, Rovo 기반의 Teamwork Collection을 중심으로 업무·지식·커뮤니케이션을 하나의 플랫폼에서 연결하는 방향을 강화하고 있습니다.
협업 업무 환경은 어떻게 변화하고 있을까
가트너 보고서에서는 최근 협업 업무 관리 시장의 주요 변화로 다음과 같은 요소를 강조하고 있습니다.
부서 간 협업 강화
중앙 집중형 문서 및 업무 관리
AI 기반 자동화 및 업무 지원
실시간 업무 가시성과 인사이트
분산된 업무 도구 통합
특히 AI와 생성형 AI(GenAI)의 활용은 단순 자동화를 넘어 업무 추천, 작업 생성, 프로젝트 요약, 리스크 예측 등으로 빠르게 확장되고 있습니다.
또한 여러 도구를 오가며 업무를 처리하는 방식 대신, 하나의 플랫폼 안에서 업무와 정보를 연결하려는 요구도 점점 커지고 있습니다.
Atlassian이 Gartner 리더로 선정된 이유
가트너는 Atlassian의 강점으로 글로벌 시장 입지, 확장성 높은 생태계, 개발자 및 파트너 지원 구조 등을 언급했습니다.
특히 Atlassian은 Teamwork Graph와 Rovo 기반 AI 플랫폼을 중심으로 Atlassian 제품과 외부 애플리케이션 데이터를 연결하고, 보다 통합된 사용자 경험을 제공하는 방향으로 제품 전략을 확장하고 있습니다.
Jira 기반 업무 관리
Jira는 개발 조직뿐 아니라 다양한 비즈니스 팀에서도 프로젝트 및 업무 관리 플랫폼으로 활용되고 있습니다.
워크플로우 관리, 이슈 추적, 자동화 기능 등을 통해 조직 내 업무 흐름을 표준화하고 협업 효율성을 높일 수 있습니다.
Confluence 기반 지식 공유
Confluence는 조직 내 문서화와 지식 공유를 위한 중앙 협업 공간 역할을 수행합니다.
회의록, 운영 가이드, 프로젝트 문서, 정책 자료 등을 통합 관리할 수 있어 정보 접근성과 협업 생산성을 높일 수 있습니다.
Loom 기반 비동기 협업
Loom은 영상 기반 커뮤니케이션을 통해 비동기 협업 환경을 지원합니다.
반복적인 회의를 줄이고 설명 중심의 커뮤니케이션을 간소화할 수 있어 원격 및 글로벌 협업 환경에서 활용도가 높아지고 있습니다.
Rovo 기반 AI 업무 지원
Atlassian은 Rovo와 Teamwork Graph 기반 AI 기능을 통해 여러 시스템에 분산된 업무 데이터를 연결하고 있습니다.
이를 통해 사용자는 필요한 정보를 빠르게 검색하고, 업무 맥락 기반 추천과 자동화를 지원받을 수 있습니다.
Atlassian이 만드는 통합 협업 환경
가트너는 협업 업무 관리 시장의 핵심 트렌드 중 하나로 “통합 플랫폼”과 “중앙 협업 허브”를 강조하고 있습니다.
Atlassian 역시 개별 제품 중심이 아니라 Teamwork Collection 중심의 통합 경험을 강화하고 있으며, 업무·문서·AI·커뮤니케이션을 연결하는 방향으로 플랫폼 전략을 확대하고 있습니다.
특히 대규모 조직에서는 업무 표준화, 협업 가시성, 운영 효율성, AI 활용성이 중요한 요소로 자리잡고 있으며, 이러한 흐름 속에서 Atlassian의 통합 플랫폼 전략이 더욱 주목받고 있습니다.
마무리
이번 Gartner® Magic Quadrant™ 리더 선정은 Atlassian이 단순 협업 도구 제공을 넘어 조직 전체의 업무 운영과 협업 방식을 연결하는 플랫폼으로 확장되고 있다는 점을 보여줍니다.
협업 환경이 점점 복잡해지는 상황에서, 업무·지식·AI를 하나로 연결하는 플랫폼의 중요성은 앞으로 더욱 커질 것으로 보입니다.
Sonar는 2026년 5월 21일, AI 네이티브 코드 리뷰 플랫폼 Gitar를 인수했다고 발표했습니다. 이번 인수를 통해 Sonar는 AI 코드 리뷰 기능을 SonarQube의 코드 검증 플랫폼과 통합하고, 에이전틱 개발 시대에 맞춘 코드 검증 역량을 확장할 계획입니다.
Sonar에 따르면 SonarQube는 AI가 생성한 코드의 품질, 보안, 아키텍처 무결성을 보장하기 위해 7백만 명 이상의 개발자와 AI 에이전트가 사용하고 있습니다.
또한 Fortune 100 기업의 75% 이상이 SonarQube를 활용하고 있으며, Sonar를 사용하는 팀은 AI 생성 코드로 인한 장애를 경험할 가능성이 44% 낮고, SonarQube로 정리된 코드베이스는 AI 에이전트의 토큰 사용량을 최대 8%까지 줄일 수 있다고 밝혔습니다.
Gitar는 GitHub와 GitLab의 Pull Request 안에서 코드, 버그, CI 실패를 자동으로 수정하고 검증하는 AI 기반 코드 리뷰 및 검증 플랫폼입니다.
Sonar는 Gitar를 코드 생성 이후 단계에서 작동하는 에이전틱 품질 게이트로 설명하며, 소프트웨어 팀의 수동 리뷰 부담을 줄이고 지능적인 수정 방안을 제공한다고 소개했습니다.
이번 인수 이후 Gitar의 공동 창업자인 Ali-Reza Adl-Tabatabai와 Gautam Korlam은 Sonar에 합류해 Gitar 플랫폼 개발을 이끌 예정입니다.
Gitar는 기존 고객에게 영향 없이 독립 제품으로 계속 제공되며, 향후 SonarQube 및 SonarQube Advanced Security와 함께 구매할 수 있습니다.
Sonar는 이번 인수를 통해 코드베이스의 구문, 데이터 흐름, 로직 흐름, 제어 흐름, 아키텍처, 의존성을 분석하고, 조직 고유의 표준을 정확하고 일관되며 반복 가능하고 감사 가능한 방식으로 적용할 수 있다고 설명했습니다.
또한 식별된 이슈를 에이전틱 방식으로 수정하고, AI 에이전트가 코드를 작성하는 과정과 CI 워크플로우 안에서 이를 수행할 수 있다고 밝혔습니다.
Sonar는 이번 Gitar 인수를 통해 AI 코드 리뷰와 코드 검증 엔진을 하나의 플랫폼으로 결합하고, AI 에이전트가 코드를 작성하는 순간부터 코드베이스에 반영되는 시점까지 검증할 수 있는 환경을 제공하겠다는 방향을 제시했습니다.
이는 AI와 에이전틱 코딩 환경에서 소프트웨어 품질을 높이고, 배포 신뢰도를 강화하며, 코드 작성 시간과 토큰 비용을 줄이기 위한 전략으로 볼 수 있습니다.
에이전틱 기반 개발 시대의 Sonar 혁신
Gitar 인수는 AI 에이전트가 신뢰할 수 있고, 일관되며, 투명한 방식으로 작동하도록 보장하기 위한 Sonar의 방법론인 Agent Centric Development Cycle(AC/DC) 전반에 걸쳐 가치를 제공하겠다는 Sonar의 의지가 한층 강화되었음을 보여줍니다.
지난 12개월 동안 Sonar는 다음과 같은 새로운 제품과 기능을 포함하도록 제품 포트폴리오를 확장해 왔습니다.
- SonarQube Advanced Security는 종속성을 인식하는 고급 정적 애플리케이션 보안 테스트(SAST)와 소프트웨어 구성 분석(SCA)을 통해 소프트웨어 공급망까지 검증 범위를 확장합니다.
- SonarQube Agentic Analysis는 SonarQube의 기능을 에이전틱 자체 검증에 적용하여, AI 에이전트가 조직의 품질 기준에 맞춰 자신의 작업을 실시간으로 점검할 수 있도록 합니다. 이를 통해 이후의 추론 작업에서 문제가 누적되는 것을 방지합니다.
- SonarQube Architecture는 AI 에이전트와 개발자 모두에게 엄격한 아키텍처 표준을 적용하여, AI가 생성한 코드가 구조적 취약성을 유발하지 않고 기존 시스템에 깔끔하게 통합되도록 보장합니다.
- SonarQube MCP Server는 AI 에이전트를 SonarQube의 분석 엔진에 실시간으로 연결합니다. 이를 통해 Claude Code, GitHub Copilot, Cursor, Devin과 같은 도구가 기존 워크플로우를 벗어나지 않고도 코드 품질과 보안 이슈를 평가할 수 있습니다.
- SonarQube CLI는 에이전틱 환경을 위한 명령줄 인터페이스로, AI 에이전트가 생성하는 모든 코드 조각을 실시간으로 스캔하고, 세션 토큰, API 키 및 기타 민감한 자격 증명이 LLM 제공업체에 전달되기 전에 자동으로 차단합니다.
- SonarQube Plugin for Claude Code는 Sonar의 전체 코드 검증 분석 기능을 Anthropic의 Claude Code 안으로 가져오는 단일 설치형 구성 요소입니다. SonarQube CLI, MCP Server, 훅, 슬래시 명령어, 시크릿 스캔 기능을 함께 제공합니다.
- SonarQube Remediation Agent는 식별된 이슈에 대해 검증된 수정안을 제공하여, 탐지부터 해결까지의 과정을 완결합니다.
- Sonar Context Augmentation은 코드가 작성되기 전부터 AI 에이전트에 적절한 맥락, 가드레일, 조직 표준을 제공하여 처음부터 품질을 내재화하고 테스트 통과율을 크게 향상시킵니다.
- SonarSweep은 엔터프라이즈 맥락을 파인튜닝된 모델에 직접 내장하여, LLM 출력물의 보안 취약점을 최대 67%까지 줄이고, 검증이 필요해지기 전에 코드 생성 단계에서 문제를 바로잡습니다.
서비스 관리 영역에서 AI는 더 이상 ‘언젠가 도입할 기술’이 아니라, 이미 실무에 적용되고 있는 변화입니다.
Atlassian은 조사를 위해 미국 전체 500여 명의 비즈니스 전문가를 대상으로 서비스 관리 영역에서 AI의 활용과 관련한 기업들의 경험과 인식에 관해 설문조사를 실시했습니다.
이 내용을 토대로 하여, 빠르게 진화하는 AI 기반 세상을 조사하고 AI가 팀에 도움이 될 방법을 확인하는 데 벤치마크를 확립할 수 있습니다.
- 고객 만족도 챔피언인 AI: AI 도입의 가장 큰 동인은 고객 경험 향상으로, 조직의 64%가 이 목표를 우선 순위로 삼고 있으며, 79%가 AI 기술을 통해 고객 서비스 제공이 개선되고 있다고 답했습니다.
가상 에이전트, 개인화된 셀프 서비스 솔루션 등의 AI 기반 도구 덕분에 기업이 더 빠르고 궁극적으로 만족도가 높은 맞춤형 고객 상호 작용을 창출할 수 있게 되었습니다. - 업무 효율을 증대하는 AI: AI가 직원 생산성에 미치는 영향은 놀라운데, 응답자의 78% 가 효율이 향상되었다고 답했습니다.
AI는 일상적인 작업을 자동화하고 지능형 지원을 제공하여 직원이 더 전략적이고 창의적인 업무에 집중할 수 있는 귀중한 시간을 확보해 줍니다. - 데이터 기반 의사결정을 촉진하는 AI: 무려 응답자의 80%가 AI 덕분에 더 현명하고 효과적인 의사결정을 내릴 수 있게 되었다고 답했습니다.
조직들은 방대한 데이터를 분석하고 실행 가능한 인사이트를 도출하는 AI의 기능을 활용하여 경쟁 우위를 확보하고 더 나은 비즈니스 실적을 내고 있습니다.
Atlassian의 서비스 관리 영역 AI 현황 보고서에 따르면 조직의 88%가 이미 서비스 관리에 AI를 활용하고 있으며, 향후 12개월 동안 AI 기술 투자를 확대하거나 심화할 계획이라고 답한 조직도 89%에 달했습니다.
AI 도입의 주요 목적은 고객 경험 개선, 효율 향상, 데이터 기반 의사결정 강화로 나타났습니다. 이러한 흐름 속에서 Jira Service Management는 IT, 운영, HR, 고객 서비스 등 다양한 팀이 AI를 실제 업무에 적용할 수 있도록 지원합니다.
Atlassian의 AI 기반 서비스 관리 페이지에서도 AI를 통해 지원 및 운영 팀이 이슈를 예측하고, 조치를 제안하며, 해결책을 자동화해 인사이트를 행동으로 전환할 수 있다고 설명합니다.
Atlassian과 함께하면 일상 업무에 진정한 변화를 불러오는 실질적이고 영향력 있는 AI 개선이 가능합니다. 출시될 기능과 이러한 솔루션은 그저 유행에 편승한 것이 아니라 조직 전체의 서비스 제공을 개선하기 위해 마련된 실용적인 도구입니다.
AI 기반 기능을 활용해 조직을 혁신할 수 있도록, Atlassian의 AI로 개발, IT 및 비즈니스 팀의 역량을 강화하고 팀끼리 서로 연결하는 방법을 자세히 살펴보겠습니다.
서비스 관리는 더 이상 IT만의 일이 아닙니다
과거 서비스 관리는 주로 ITSM, 즉 IT 서비스 관리의 영역으로 이해되는 경우가 많았습니다. 하지만 지금은 HR, 법무, 시설, 재무, 고객 지원 등 조직 전반의 요청과 업무 흐름을 연결하는 방식으로 확장되고 있습니다.
직원은 필요한 정보를 더 빠르게 찾고 싶어 하고, 지원팀은 반복적인 문의를 줄이고 더 중요한 문제 해결에 집중하고 싶어 합니다. 관리자는 서비스 품질을 유지하면서도 응답 속도와 운영 효율을 높여야 합니다. 이 균형을 맞추는 데 AI 기반 서비스 관리가 중요한 역할을 할 수 있습니다.
Jira Service Management의 AI 기반 기능은 직원 헬프 센터 개선, 액세스 제어, HR 앱 연동, AI 생성 요청 유형과 템플릿, 요청 요약, 다음 단계 추천, 다국어 가상 서비스 에이전트 등으로 구성됩니다.
이를 통해 직원은 Slack, Microsoft Teams, 이메일, 웹 위젯, 헬프 센터 등 다양한 채널에서 필요한 지원을 받을 수 있습니다.
AI는 서비스 관리에서 무엇을 바꾸고 있을까
Atlassian의 조사 결과를 보면 AI는 단순 자동화를 넘어 서비스 품질과 의사결정 방식까지 바꾸고 있습니다. 응답자의 80%는 AI가 데이터 기반 의사결정 능력을 향상시켰다고 답했으며, 79%는 고객 서비스 제공 능력이 개선되었다고 답했습니다.
또한 78%는 AI 도입이 직원 업무 효율성에 긍정적인 영향을 미쳤다고 응답했습니다. 이 수치는 AI가 단지 업무를 빠르게 처리하는 도구가 아니라, 조직이 더 정확하게 판단하고 더 일관된 서비스를 제공하도록 돕는 기반이 되고 있음을 보여줍니다.
예를 들어 고객 서비스에서는 AI 기반 가상 에이전트가 반복적인 문의를 처리하고, 자동화된 티켓 분류와 라우팅을 통해 담당자가 더 빠르게 문제에 접근할 수 있도록 돕습니다.
IT 운영에서는 인시던트 감지, 유사 인시던트 그룹화, 우선순위 판단, 적합한 대응 담당자 추천 등을 통해 보다 빠른 대응이 가능해집니다.
R&D 부서에서는 프로젝트 일정 관리, 리스크 예측, 코드 품질 분석 등 개발 수명 주기 전반에 AI가 활용되고 있습니다.
중요한 것은 ‘도입’보다 ‘활용 전략’입니다
AI 도입이 빠르게 확산되고 있지만, 모든 조직이 같은 속도와 방식으로 AI를 활용하고 있는 것은 아닙니다.
AI 도입의 주요 과제로 데이터 프라이버시와 보안, 스킬 및 인재 부족, 예산 제약, 데이터 품질 문제 등이 있습니다. 특히 응답자의 72%가 AI 도구 보안에 대한 우려를 표시한 점은 AI 활용에서 신뢰성과 거버넌스가 얼마나 중요한지를 보여줍니다.
따라서 AI 기반 서비스 관리는 단순히 새로운 기능을 추가하는 문제가 아닙니다. 어떤 요청을 자동화할 것인지, 어떤 데이터와 지식 기반을 연결할 것인지, 어떤 업무는 사람의 판단이 필요한지 구분해야 합니다.
또한 AI가 제안하는 내용을 팀의 실제 프로세스와 어떻게 연결할지도 함께 설계해야 합니다.
AI 기반 서비스 관리는 이미 현실입니다
서비스 관리에서 AI의 가치는 반복 업무를 줄이는 데서 끝나지 않습니다. 직원은 필요한 지원을 더 빠르게 받고, 에이전트는 맥락을 파악하는 시간을 줄이며, 관리자는 데이터 기반으로 서비스 품질을 개선할 수 있습니다.
IT 운영은 인시던트 대응 속도를 높이고, HR은 온보딩과 오프보딩 같은 반복 프로세스를 더 체계적으로 운영할 수 있습니다. 결국 AI 기반 서비스 관리는 조직의 업무 방식을 더 빠르고, 일관되고, 연결된 방식으로 바꾸는 전략입니다.
Jira Service Management는 이러한 변화를 실무에 적용할 수 있도록 AI 기반 직원 지원, AIOps, HR 서비스 관리, 가상 서비스 에이전트, 요청 요약 및 자동화 기능을 하나의 플랫폼 안에서 제공합니다.
AI를 어떻게 도입할지 고민하고 있다면, 이제 질문은 “AI를 사용할 것인가”가 아니라 “우리 조직의 서비스 관리 흐름에서 AI를 어디에, 어떻게 연결할 것인가”가 되어야 합니다.
서비스 요청이 많아질수록, 팀 간 협업이 복잡해질수록, AI 기반 서비스 관리는 더 빠른 응답과 더 나은 경험을 만드는 핵심 기반이 될 수 있습니다.
Jira Service Management가 제공하는 AI 기반 업무 경험
Jira Service Management의 강점은 AI를 별도의 복잡한 시스템으로 분리하지 않고, 실제 서비스 관리 흐름 안에 자연스럽게 연결한다는 점입니다.
서비스 데스크를 빠르게 구성하고, 팀별 요구에 맞춰 조정하며, 자연어 기반 자동화와 AI 기반 프로젝트 구성을 통해 필요한 업무 흐름을 빠르게 만들 수 있습니다.
이를 통해 기존 ITSM 솔루션의 복잡성 없이 빠르게 가치를 창출할 수 있습니다. 특히 AI 기반 직원 지원 기능은 내부 서비스 경험을 크게 개선할 수 있습니다.
가상 서비스 에이전트는 지식 문서를 기반으로 답변을 제공하고, 모든 주요 언어를 지원해 글로벌 조직에서도 일관된 지원 경험을 만들 수 있습니다. 또한 AI가 생성한 요청 요약, 권장 단계, 원클릭 실행 버튼은 에이전트가 상황을 빠르게 파악하고 다음 조치를 취하도록 돕습니다.
IT 운영 측면에서는 AIOps 기능이 중요한 역할을 합니다. 개발 팀과 운영 팀을 단일 AI 기반 플랫폼에서 연결하고, 변경 사항과 인시던트, 요청을 함께 관리함으로써 리스크를 줄이고 대응 속도를 높일 수 있습니다.
Jira Service Management의 10가지 핵심 AI 슈퍼파워
Jira Service Management는 Atlassian 플랫폼의 최고 AI 첨단 기술을 선보이므로 고객이 가치를 창출하는 데 걸리는 시간이 매우 짧습니다.
이러한 AI 슈퍼파워는 현재 이미 사용할 수 있거나 향후 추가될 예정입니다. 종류는 두 가지로, 플랫폼에 직접 빌드된 사전 대비적 AI 경험, 그리고 IT 서비스, 직원 지원, HR 서비스 관리 등에 도움이 되는 전문 AI 에이전트입니다.
1. 직원 헬프 센터가 대폭 향상됩니다.
새롭게 개선된 HR 헬프 센터에서는 리소스가 눈에 잘 띄는 위치에 있습니다. 직원은 이제 필요한 내용을 더 빠르게 찾을 수 있습니다.
2. 효과적인 통제: 간소화된 액세스 제어.
민감한 HR 요청이 있나요? 문제없습니다. 간소화된 액세스 제어로 기밀 정보의 보안을 유지하면서 적절한 인력이 필요한 내용을 확인하도록 할 수 있습니다.
3. 원활한 HR 통합으로 지원이 용이해집니다.
Workday, Okta 등 주요 HR 앱으로 Jira Service Management에 연결할 수 있습니다. 간소화된 지원과 더 매끄러운 워크플로도 가능하냐고요? 물론입니다.
4. 귀사를 위한 AI 기반 인력 파트너.
온보딩부터 오프보딩에 이르기까지 모든 단계가 더 쉬워집니다. HR 팀은 AI 생성 요청 유형 및 템플릿을 통해 그 어느 때보다 빠르게 서비스 데스크를 준비할 수 있습니다.
5. 헬프 데스크를 위한 개인 코치.
이제 가상 서비스 에이전트에 성과 통계 및 지식 간극이 표시되는 AI 기반 대시보드가 제공됩니다. 이 대시보드에서는 해당 간극을 채우기 위한 새로운 문서도 제안해 줍니다.
6. 즉각적인 명확성.
이제 AI가 생성한 요약에서 직원 요청 개요, 다음 단계 추천 및 원클릭 실행 버튼까지 제공됩니다. 클릭 횟수는 줄어들고 문제는 더 빠르게 해결할 수 있습니다.
7. 마법 같은 다국어 기능.
이제 가상 서비스 에이전트가 모든 주요 언어를 지원하므로 전 세계 직원이 필요한 도움을 받을 수 있습니다.
8. 업무 위치에 관계없이 가능한 직원 지원.
Slack, Teams, 이메일, 웹 위젯, 헬프 센터 등 직원이 어디에서 업무를 처리하든 가상 서비스 에이전트의 도움을 받을 수 있습니다.
9. 에이전틱(AI 에이전트) 도우미를 소개합니다.
근본 원인을 식별하고 인시던트 사후 검토를 작성하는 등, 새로운 AI 에이전트가 복잡한 작업을 처리해 주므로 팀이 큰 그림에 집중할 수 있습니다.
10. 개선된 IT 운영!
인시던트가 발생하면 AI가 과거 인시던트, 우선 순위 수준, 변경 리스크에 대해 안내하고, 최적의 대응 담당자까지 제안해 줍니다.
관련 자료 다운로드
출처:
Four warning signs your AI and collaboration investments aren’t paying off
작성자:
kdelara
발행일: 2026년 04월 13일
96%의 기업이 AI로부터 의미 있는 비즈니스 가치를 아직 얻지 못하고 있습니다.
그리고 여러분의 조직 역시 그중 하나일 수 있습니다.
그럼에도 IT 리더들은 계속해서 큰 규모의 투자를 이어가고 있으며, 프로젝트 지연과 서비스 지표 개선 부진의 원인을 고민하고 있습니다.
Atlassian의 AI Collaboration Index에 따르면, 광범위한 투자에도 불구하고 96%의 기업이 아직 AI에서 의미 있는 비즈니스 가치를 확인하지 못했습니다.
AI는 업무 수행을 더 쉽게 만들었지만, 협업을 더 쉽게 만들지는 못했습니다.
이 내용이 불편하게 느껴진다면, 이미 여러분은 다음의 네 가지 경고 신호 중 하나(또는 그 이상)에 해당하고 있을 가능성이 있습니다.
이 네 가지 경고 신호는 독립적인 문제가 아니라 하나의 흐름을 이루는 단계입니다.
하나를 경험하고 있는 대부분의 IT 조직은 이미 다음 단계로 이동하고 있습니다.
그리고 그 단계가 깊어질수록 AI 투자와 실제 ROI 사이의 격차는 더욱 커집니다.
1. 개인은 더 빨라지고, 팀은 더 느려진다
이론적으로 AI는 IT에 있어 게임 체인저가 되어야 합니다.
더 빠른 장애 분류, 더 나은 근본 원인 분석, 더 정리된 문서화, 그리고 더 효율적인 변경 관리까지 가능해야 합니다.
하지만 실제로는 많은 IT 리더들이 전혀 다른 현실을 경험하고 있습니다:
개별 구성원은 더 많은 티켓과 문서, 그리고 다양한 “업무 산출물(work artifacts)”을 만들어냅니다.
로컬 수준의 작업은 더 빠르게 처리됩니다.
하지만 엔드투엔드 프로젝트 일정과 서비스 지표는 거의 변화가 없습니다.
이것이 IT에서 나타나는 AI 효율성의 역설입니다:
AI는 분절된 시스템 안에서 개별 작업의 속도를 높이지만, 연결된 업무 방식이 없다면 이러한 개선은 조직 전체의 의미 있는 성과로 이어지지 않습니다.
AI 도입이 단순히 코드 추천이나 문서 요약 같은 “개인 생산성” 중심의 사용 사례에만 집중되어 있고, 팀 간 업무 흐름을 바꾸지 않는다면, 실제로는 잘못된 대상을 최적화하고 있을 가능성이 높습니다.
팀에서는 다음과 같은 모습으로 나타날 수 있습니다:
AI는 깔끔한 PIR(사후 사고 보고서)을 초안으로 작성하지만, incident commander는 이를 읽기 전에 4개의 도구를 오가며 컨텍스트를 찾는 데 40분을 소비합니다.
에이전트는 단순한 티켓 처리량을 두 배로 늘렸지만, 주요 장애의 MTTR은 거의 변하지 않았는데, 그 이유는 핸드오프와 책임 소유가 여전히 불명확했기 때문입니다.
이 지점에 있다면, 잘 되고 있는 것을 단순히 확장하면 해결될 것이라고 생각할 수 있습니다.
하지만 바로 그 접근이 다음 경고 신호를 촉발합니다.
해결책: AI에 목표 맥락 제공
평균 해결 시간(MTTR), 서비스 수준 계약(SLA) 준수율, 고객 만족도(CSAT)와 같은 측정 가능한 성과 지표에서 시작해 이를 AI 도구에 컨텍스트와 기준으로 제공합니다.
조직의 목표를 중앙 컨텍스트 그래프에 통합하면, 각 AI의 동작과 응답은 더 정확해지고 이후 상황을 더 잘 예측할 수 있게 됩니다.
2. 병목은 해결되지 않은 채 옮겨졌다
아마 팀의 작업 속도는 더 빨라졌을 것입니다.
하지만 처리량은 이후 리뷰, 승인, 또는 팀 간 조율 단계에서 다시 병목이 발생하며, 실제 제약이 실행에서 거버넌스와 의사결정으로 이동했음을 보여줍니다.
AI는 더 많은 RFC, 변경 요청, PIR, 서비스 요청을 생성하지만, 검토와 승인 워크플로가 여전히 수동적이고 분절되어 있다면 결국 병목은 해결되지 않은 채 옮겨졌을 뿐입니다.
변경 자문 위원회는 AI가 생성한 기록에 파묻히고, 보안 및 리스크 팀은 쏟아지는 요청에 압도되며, 리더십의 인박스에는 AI로 정리된 비즈니스 케이스가 쌓이지만 여전히 실질적인 정합성은 부족한 상태입니다.
팀에서는 다음과 같은 모습으로 나타날 수 있습니다:
변경 요청은 하룻밤 사이 두 배로 늘어나지만, CAB는 여전히 주간 단위로 운영됩니다.
리스크와 영향도가 한 곳에서 보이지 않기 때문에 승인 작업이 며칠씩 쌓이고, 그 사이 출시 일정은 지연되며, 리더들은 AI가 ‘다음번에는 더 빨라질 것’이라고 기대하게 됩니다.
이 시점에서 많은 리더들은 새로운 병목을 해결하기 위해 AI 투자를 더 강화하게 됩니다.
하지만 그 아래에 의도적으로 설계된 워크플로 시스템이 없다면, 이러한 가속은 오히려 더 큰 문제를 만들어냅니다.
해결책: AI로 인한 병목을 고려한 사전 작업 설계
서비스, 소프트웨어, 인프라 전반을 아우르는 하나의 연결된 관점을 정의합니다.
또한 새로운 용량 제약을 고려하기 위해, AI가 생성한 작업(코드, PIR, 지식 베이스 콘텐츠 등)에 대해 사람의 검토가 필요한 지점을 식별합니다.
3. AI는 혼란을 더 키우고 있다
이미 작업이 여러 도구와 팀에 걸쳐 파편화되어 있는 상태에서 AI를 도입하면, 오히려 이러한 파편화가 더 심화될 수 있습니다.
연결되지 않은 시스템 사이를 오가는 콘텐츠와 추천의 양이 증가하면서, 사람들이 올바른 맥락을 찾고 확신을 가지고 행동하기가 더 어려워집니다.
즉, 맥락 없는 AI는 노이즈를 증폭시킵니다.
팀에서는 다음과 같은 모습으로 나타날 수 있습니다:
가상 에이전트는 ‘관련 있어 보이는’ 문서 3개를 제안하지만, 모두 오래된 정보입니다.
엔지니어들은 어떤 런북을 신뢰해야 할지 논쟁하는 동안에도 인시던트 시간은 계속 흘러갑니다. AI가 실패한 것이 아니라, 신뢰해야 할 정보의 기준(source of truth)이 문제였습니다.
조직 내에서 업무가 어떻게 흐르는지, 어떤 시스템이 현재의 단일 정보원(source of truth)을 담고 있는지, 그리고 목표·정책·표준이 어떻게 관리되고 최신 상태로 유지되는지에 대한 명확함 없이 운영된다면, AI는 이미 혼란스러운 워크플로 위에 또 하나의 잡음을 더하는 요소에 불과하게 됩니다.
여기까지 도달했다면, 아마도 불편한 사실 하나를 깨닫기 시작했을 것입니다.
해결책: 조직 맥락을 기반으로 AI 작업 시스템 구성
위키, 파일 공유, 엔터프라이즈 채팅 전반에 걸쳐 조직의 지식을 통합하는 컨텍스트 그래프에 투자하세요.
이를 단일 정보원으로 활용해 런북, PIR, 표준을 최신 상태로 유지하고, KB 문서 및 자산과 연결합니다.
4. AI 이전과 다르지 않은 방식으로 일하는 팀
여기에는 불편한 진실이 있습니다.
앞선 세 가지 경고 신호는 사실 AI 자체의 문제가 아니라 조직의 시스템 문제였습니다.
조직 구조, 승인 체계, 그리고 파편화된 런북(runbook)과 암묵적 지식의 문제입니다.
AI가 무언가를 망가뜨린 것이 아니라, 이미 존재하던 균열을 더 이상 무시할 수 없게 만들었을 뿐입니다.
이제 AI는 잘못된 인계, 불명확한 소유권, 그리고 사일로화된 의사결정을 기계의 속도로 그대로 재현하고 있습니다.
더 냉정한 현실은, AI는 맥락이 없는 상태에서는 IT 조직의 기존 파편화를 해결할 수 없다는 것입니다.
서비스, 소프트웨어, 인프라 팀이 서로 단절된 워크플로와 데이터 모델 위에서 운영될 때, AI는 그 단절을 그대로 반영할 뿐 아니라 인시던트, 변경, 프로젝트 업무 전반에서 오히려 이를 증폭시키는 경우가 많습니다.
결과를 바꾸려면 리더들이 먼저 소유권, 거버넌스, 그리고 크로스 툴 통합 구조를 재설계해야 하며, 그래야만 AI가 단순히 파편화를 가속하는 시스템이 아니라, 일관된 시스템을 강화하는 방향으로 작동할 수 있습니다.
팀에서는 다음과 같은 모습으로 나타날 수 있습니다:
여러 도구에 AI를 도입했지만, 목표는 여전히 슬라이드 자료에 머물러 있고 승인 과정은 이메일 인박스에 남아 있습니다.
사람들은 여전히 작년과 같은 플레이북을 따르고 있을 뿐이며, 단지 더 빠르게 움직일 뿐이기 때문에 결과는 달라지지 않습니다.
해결책: AI와 함께 일하는 팀의 업무 방식 재설계
AI의 출력 품질이 향상됨에 따라, 워크플로에서 더 장기적으로 수행되는 작업의 책임자로 AI를 도입하는 방안을 고려해야 합니다.
먼저 팀이 달성하고자 하는 원칙을 정의해야 하며, 여기에는 목표, 결과물의 품질, 그리고 성공 기준이 포함됩니다.
이후 반복적인 실험과 테스트를 통해 AI가 어떤 영역의 작업을 수행할 수 있는지 확인하고, 사람은 검토와 판단을 담당하는 구조로 점진적으로 확장해 나갑니다.
왜 AI만으로는 이러한 문제를 해결할 수 없는가
이 단계에서 자신의 팀이 해당된다고 느낀다면, 이미 그 궤적을 직접 확인한 것입니다.
패턴은 분명합니다.
AI는 조직 설계와 워크플로의 파편화를 해결할 수 없습니다.
깨진 시스템 위에 AI를 더 많이 쌓아도 제약 조건은 단지 다른 곳으로 이동할 뿐입니다.
진정한 ROI를 얻기 위해서는 먼저 일하는 방식을 바로잡아야 합니다.
이 지점에서 연결된 시스템 오브 워크(System of Work)를 구축하는 것이 핵심이 됩니다.
Atlassian의 System of Work는 기술 팀과 비즈니스 팀을 연결해 업무 속도를 높이고 임팩트를 극대화하도록 돕는 데이터 기반 철학입니다.
이는 네 가지 원칙을 기반으로 합니다.
목표에 맞춰 업무를 정렬
함께 업무를 계획하고 추적
집단 지식 활용
AI를 팀의 일부로 포함
IT 리더들이 이러한 원칙을 적용하면, AI와 협업 도구는 더 이상 개별적인 포인트 솔루션에 머무르지 않고, 성과 중심으로 조정된 통합된 시스템의 일부가 됩니다.
경고 신호를 로드맵으로 전환하기
이 원칙들이 함께 적용되면 이러한 경고 신호는 실행 계획으로 전환됩니다.
실질적인 AI 투자 성과를 내고 있는 조직들은 더 좋은 도구를 구매하는 것에서 시작하지 않았습니다.
대신 팀 간 업무 흐름을 재설계하는 것에서 출발했습니다.
무엇이 이들을 다르게 만드는지 알고 싶으신가요?
AI Collaboration Index는 상위 4% 조직이 무엇을 다르게 하는지, 그리고 AI 투자와 실제 영향 사이의 격차를 어떻게 줄일 수 있는지를 설명합니다.
출처:
Creating with Rovo: How We Built a Collaborative AI Canvas
작성자:
Alex Knight (Sr. Principal Engineer)
Abhi Kishore
발행일: 2026년 04월 06일
Rovo는 플랫폼의 핵심에 있는 핵심 AI 솔루션입니다.
Teamwork Graph를 통해 Confluence, Jira 및 연결된 앱과 같은 도구 전반에서 내부 및 외부 지식을 검색하고, 필요한 정보를 적절히 찾아 제공합니다.
또한 Jira 이슈부터 Confluence 페이지까지 생태계 전반의 객체를 생성하고 상호작용할 수도 있습니다.
하지만 Rovo에는 아직 완전한 기능을 갖춘 생성 캔버스가 없었습니다:
사람과 AI가 함께 실시간으로 콘텐츠를 공동 생성하고, 반복적으로 개선하며, 정교하게 다듬을 수 있는 협업 공간이 부족했던 것입니다.
이러한 공백이 “Creating content with Rovo”의 출발점이 되었습니다.
Rovo로 창작한다는 핵심 아이디어는 단순합니다:
콘텐츠 생성은 AI와 사용자의 협업이어야 하며, 한쪽이 다른 쪽에 작업을 넘기는 방식이어서는 안 된다는 것입니다.
이 글에서는 Rovo를 활용한 콘텐츠 생성의 내부 과정을 살펴보고, 다음 내용을 다룹니다:
이를 왜 협업형 AI 캔버스로 설계했는지, 그리고 왜 단발성 작성 도구(one-shot writer)가 아닌지를 설명합니다.
페이지, 화이트보드, 데이터베이스 등 다양한 콘텐츠 유형을 안정적으로 처리하는 방법을 다룹니다.
ADF, SVG, CSV 기반 스키마에 대한 기술적 설계 선택을 설명합니다.
Rovo가 풍부한 콘텐츠를 안전하게 생성하고 실시간으로 편집할 수 있도록 하는 스트리밍 인프라 구조를 소개합니다.
핵심 원칙
우리는 단일 제품 안에 고립된 독립형 AI 작성 도구를 만들고자 하지 않았습니다.
Rovo로 콘텐츠를 만드는 기능은 Confluence에서 시작할 수 있지만, 본질적으로 Rovo 위에서 네이티브하게 구축되어 있으며 모든 Rovo 환경에서 접근할 수 있습니다.
콘텐츠 생성은 채팅 경험의 자연스러운 확장처럼 느껴져야 합니다. 사용자는 하나의 대화 안에서 질문하고, 페이지를 공동 작성하고, 화이트보드를 반복적으로 개선하며, 데이터베이스를 정교하게 다듬을 수 있습니다.
이 모든 과정은 동일한 컨텍스트를 이해하는 동일한 AI와 함께 이루어집니다.
그 결과 몇 가지 핵심 설계 원칙이 도출되었습니다:
생성은 채팅 안에서 이루어집니다.
콘텐츠는 Rovo 채팅 내 캔버스에서 시작되며, 원하는 상태가 되면 적절한 공간이나 제품 영역으로 이동할 수 있습니다.
이는 기능이 아니라 플랫폼입니다.
처음부터 이 캔버스는 페이지, 화이트보드, 데이터베이스 등 다양한 콘텐츠 유형을 지원하도록 설계되었으며, 다른 제품으로 확장될 수 있도록 만들어졌습니다.
Jira 작업 항목을 위한 Create with Rovo 기능은 최근 EAP로 출시되었으며 동일한 패턴을 따릅니다.
실시간 스트리밍
사용자는 콘텐츠가 생성되고 편집되는 과정을 실시간으로 확인할 수 있습니다.
이를 통해 협업은 단순한 “생성 후 붙여넣기”가 아니라 살아 있고 반복적으로 발전하는 경험이 됩니다.
기술 구현
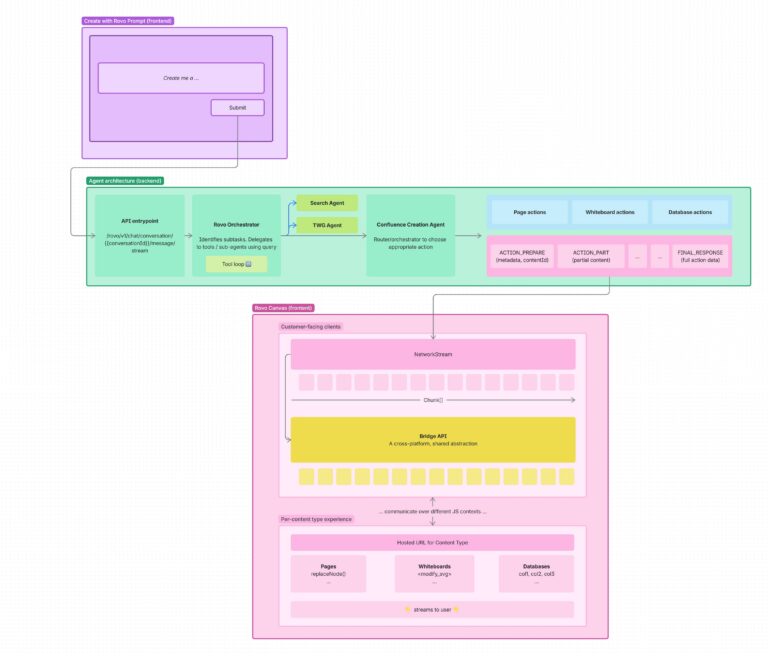
상위 수준에서 보면, Rovo의 백엔드는 상위 오케스트레이터(Orchestrator) 에이전트를 중심으로 구성되어 있으며, 이 에이전트는 여러 전문 스킬에 접근할 수 있습니다.
여기에는 크로스 프로덕트 검색(서드파티 제품 포함), Teamwork Graph 검색, Jira 조회 에이전트 등이 포함됩니다.
오케스트레이터는 사용자의 의도에 따라 이러한 스킬들을 호출합니다.
Rovo 기반 콘텐츠 생성을 지원하기 위해, Confluence 전용 생성 및 편집 스킬을 도입했습니다.
이는 다음 역할을 수행하도록 설계된 목적 특화 에이전트입니다:
사용자의 의도를 이해하고,
적절한 콘텐츠 유형과 템플릿을 선택하며,
다운스트림 시스템이 신뢰할 수 있는 구조화된 콘텐츠를 생성합니다.
이 에이전트는 독립적으로 동작하지 않습니다.
Rovo의 전체 컨텍스트를 그대로 상속하며, 여기에는 대화 기록, 연결된 지식 소스, 관련 작업 항목이 포함됩니다.
사용자는 Rovo에게 다음과 같이 요청할 수 있습니다:
“Q3 목표를 기반으로 프로젝트 계획을 생성해줘”
그러면 에이전트는 문서를 생성하기 전에 Teamwork Graph에서 적절한 컨텍스트를 먼저 가져옵니다.
LLM을 활용한 Confluence 콘텐츠 생성
Confluence 콘텐츠 유형은 각각 서로 다른 내부 표현 방식과 제약 조건을 가지고 있습니다:
페이지는 깊은 중첩을 가진 리치 노드 기반 구조를 사용합니다.
화이트보드는 공간 기반 레이아웃과 시각 요소에 의존합니다.
데이터베이스는 스키마와 뷰를 갖춘 테이블 중심 구조입니다.
품질을 극대화하기 위해 우리는 각 콘텐츠 유형에 맞는 적절한 모델과 출력 형식을 찾아야 했습니다.
이를 위해 다양한 LLM과 포맷에 대해 평가를 수행했고, 결국 각 유형에 따라 서로 다른 접근 방식을 적용하게 되었습니다.
이 과정에서는 최신 프론티어 LLM의 역량에 대한 예상치 못한 인사이트도 얻을 수 있었습니다.
페이지 / 라이브 문서
페이지의 경우, 다음과 같은 요구사항이 있었습니다:
패널, 상태, 복잡한 테이블, 매크로 등 다양한 리치 텍스트 요소를 지원하고
편집 과정에서 서식이 손실되지 않도록 합니다
페이지 생성의 경우, LLM이 ADF(중첩 JSON)를 직접 생성하도록 하고, 이를 전용 ADF 복구 라이브러리를 통해 처리합니다.
이 라이브러리는 다음과 같은 역할을 합니다:
일반적인 LLM 출력 문제(유효하지 않거나 스키마를 준수하지 않는 JSON)를 처리하고
에디터에 도달하기 전에 ADF 스키마 준수를 보장합니다
페이지 편집의 경우, LLM이 ADF를 조작할 수 있도록 에디터 스타일의 소규모 명령 집합을 정의했습니다. 예를 들어 다음과 같습니다:
replaceNode (노드 교체)
insertNodeAfter (특정 노드 뒤에 노드 삽입)
removeNode (노드 삭제)
각 도구 호출 내에서 LLM은 ADF를 값으로 생성합니다.
편집은 반성(reflection)을 포함한 에이전틱 루프(agentic loop)로 실행되며, 이는 Atlassian 문서에 특화된 코딩 에이전트와 유사하게 동작합니다.
화이트보드
화이트보드는 공간 기반 레이아웃과 시각적 의미 구조로 인해 또 다른 수준의 복잡성을 가집니다.
다음과 같은 여러 출력 형식을 평가했습니다:
HTML + CSS
WDF (화이트보드 문서 형식 – 내부 JSON 저장 표현 방식)
WDF 위에 구축된 DSL
직접적인 도구 호출
콘텐츠 생성 평가를 위해 대규모 데이터셋을 구축했으며, 사람과 LLM이(출력 스크린샷을 기반으로) 결과를 평가하도록 했습니다.
평가는 시각적 요소, 연결 구조 및 그룹화, 레이아웃 품질을 중심으로 이루어졌습니다.
또한 데이터를 파싱하고 스트리밍할 수 있는 능력도 의사결정에 영향을 주었습니다.
최종적으로 SVG가 가장 우수한 선택으로 결정되었습니다.
LLM은 방대한 데이터로 학습됩니다.
SVG가 사람들이 무한 캔버스 보드를 사고하는 방식(도형, 텍스트, 위치)과 가장 밀접하게 대응되며, LLM이 안정적으로 생성하고 이해할 수 있는 표현 방식이라는 점을 확인했습니다.
화이트보드의 경우, 다음과 같은 요구가 있었습니다:
새로운 보드를 생성할 때 SVG 문서를 생성한 다음,
이를 네이티브 화이트보드 요소로 변환합니다.
이는 거의 SVG를 가져오는(import) 것과 같은 방식입니다.

<svg viewBox="0 0 1200 800" xmlns="http://www.w3.org/2000/svg">
<rect id="background" x="0" y="0" width="1200" height="800" fill="#ffffff"/>
<text id="haiku-title" x="600" y="250" font-size="32" font-weight="bold">
<tspan x="600" dy="0">Haiku</tspan>
</text>
<text id="haiku-text" x="600" y="350" font-size="24" font-style="italic">
<tspan x="600" dy="0">Cherry blossoms fall</tspan>
<tspan x="600" dy="40">Soft petals dance on the breeze</tspan>
<tspan x="600" dy="40">Spring whispers goodbye</tspan>
</text>
<line id="decoration-line" x1="400" y1="520" x2="800" y2="520" stroke="#dfd8fd"/>
<text id="haiku-form" x="600" y="580" text-anchor="middle" font-size="14">
<tspan x="600" dy="0">5 - 7 - 5 syllables</tspan>
</text>
</svg>
LLM이 생성한 청크를 실시간으로 처리하는 과정은 스트리밍 SVG 파서와 제약 조건 해결 알고리즘을 함께 사용해 이루어지며, 요소의 포함 관계를 보장하고 레이아웃 겹침을 해결합니다.
이를 통해 사용자는 화이트보드가 실시간으로 “조립되는” 과정을 볼 수 있습니다.
편집의 경우, 다음과 같은 작업을 수행합니다:
현재 보드의 SVG 표현을 LLM에 제공하며, 라인 번호가 포함됩니다.
또한 다음과 같은 도구들을 제공합니다:
delete_svg
insert_svg
replace_svg (라인 기반)
update_elements_svg (ID 기반)
LLM이 변경 작업을 수행하기 전에 계획을 먼저 정리할 수 있도록 특별한 todo_list 도구를 도입했습니다.
이 단순한 패턴은 복잡한 다단계 편집 작업의 품질을 크게 향상시켰습니다.
todo_list
<todo_list>
모든 스티키 노트를 빨간색으로 변경
모든 스티키 노트를 왼쪽으로 이동
아래에 빨간 스티키를 더 생성
</todo_list>
편집 예시 출력 – TODO 리스트가 항상 먼저 나옵니다.
데이터베이스
데이터베이스는 LLM이 스키마, 뷰, 데이터의 세 개의 CSV로 생성하며, 이를 XML 태그로 감싸 구성됩니다.
이를 통해 스키마, 프레젠테이션(표현), 데이터가 명확하게 분리되고, 스트리밍되는 과정에서도 파싱 가능한 상태로 유지됩니다.
생성 과정에서는 모델이 항상 XML 태그로 감싸진 세 개의 CSV 섹션을 생성합니다:
<fields> – 스키마 정의:
field_name, type, depends_on, configuration<views> – 뷰 설정:
view_name, layout, filters, sorts, hidden_fields<data> – 정의된 필드에 맞는 샘플 행
편집 시에는 모델이 이 표현 방식의 데이터베이스와 사용자의 선택을 함께 입력으로 받고, 그 결과로 두 개의 CSV를 출력합니다:
메타데이터 변경 – 스키마, 뷰, 필터, 정렬
데이터 변경 – 행 추가/수정/삭제
이러한 CSV의 각 행은 하나의 선언적 변경을 나타내며, 이를 다운스트림 코드가 안정적으로 파싱하고 적용할 수 있습니다.
생성된 콘텐츠를 클라이언트로 스트리밍하기
LLM이 무엇을 생성해야 하는지를 결정하는 것은 문제의 절반에 불과했습니다.
나머지 절반은 해당 출력을 프론트엔드로 전달하는 것이었으며, 이는 점진적으로, 실시간으로, 그리고 여러 렌더링 표면에 걸쳐 이루어져야 했습니다.
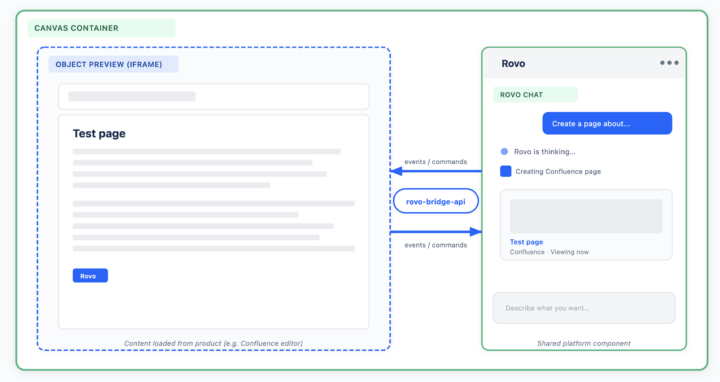
Rovo 채팅 / Rovo 캔버스 내 콘텐츠 iFrame 통신
Canvas는 전사적으로 공통으로 사용되는 Rovo Chat 플랫폼 컴포넌트를 활용합니다.
단순한 미리보기(preview)를 따로 구현하는 대신, Confluence 메인 경험에서 사용하는 것과 동일한 컴포넌트를 사용해 콘텐츠를 렌더링하며, 이를 iframe에 임베딩합니다.
이를 통해 Canvas는 Confluence의 콘텐츠 객체와 동일한 수준의 기능적 동등성(feature parity)을 갖게 됩니다.
이를 지원하기 위해 LLM 액션을 위한 새로운 스트리밍 API 계약을 정의했습니다:
LLM API는 생성되는 동안 부분 결과를 스트리밍으로 전송합니다.
프론트엔드는 이러한 부분 청크를 수집합니다.
그리고 렌더링이 필요한 콘텐츠 객체에 업데이트를 반영합니다.
프론트엔드 컴포넌트는 이를 통해 스트리밍 형태의 사용자 경험을 제공합니다.
이 기능은 Rovo가 지원하는 모든 환경에서 동작해야 합니다.
Rovo Canvas 내의 생성/편집에서도, Rovo를 통해 Confluence 콘텐츠를 직접 편집할 때와 동일한 명령을 사용했습니다.
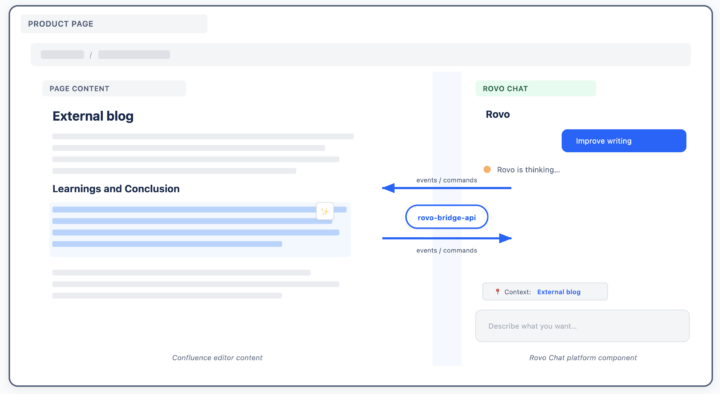
Rovo Chat을 통한 Confluence 일반 콘텐츠 편집
iFrame 내부에서 사용자는 텍스트를 선택하고 편집을 요청할 수 있으며, 해당 요청은 iFrame 외부에 있는 Rovo Chat 컴포넌트를 통해 실행되어야 합니다.
따라서 채팅과 콘텐츠 객체 간 양방향 통신 채널(bidirectional communication channel)이 필요하다는 점이 명확해졌습니다:
동일 origin 및 cross-origin 환경에서
서로 다른 JavaScript 컨텍스트 간에도
전송 계층 세부 사항이 애플리케이션 코드로 노출되지 않도록
그 결과 Rovo Bridge API가 탄생했습니다.
이는 로컬 함수 호출을 통해 서로 다른 애플리케이션이 통신할 수 있도록 하는 라이브러리이며, 그 과정에서 하위 전송 계층은 추상화됩니다.
내부 동작 구조:
전송 계층 추상화(Transport abstraction)는 데이터가 실제로 어떻게 전달될지를 결정합니다:
BrowserTransport (postMessage 기반)
DesktopTransport (Electron IPC 기반)
그리고 향후 더 추가될 다양한 방식들
명령은 강한 타입 시스템을 갖춘 Command 패턴을 따르며, 안전성을 보장합니다.
각 명령에는 추적성과 보안을 위해 sender 및 receiver 메타데이터가 포함됩니다.
데이터는 선택된 전송 계층 위에서 JSON-RPC 스펙(JSON-RPC 2.0 Specification )을 기반으로 교환됩니다.
평가 및 모니터링
오프라인 평가(offline eval)는 모든 콘텐츠 유형에 걸친 대규모 데이터셋을 활용해 매일 수행되었습니다.
이 과정에서는 스크린샷 기반의 새로운 평가 방식을 사용했으며, LLM 평가자가 작업 완료 여부뿐 아니라 시각적 품질, 톤, 지식 정확성까지 평가하도록 했습니다.
또한 결과는 항상 사람의 피드백을 기준선으로 삼아 비교되었습니다.
온라인 평가는 실제 고객 및 내부 트래픽에서 성공률과 작업 완료 지표를 추적하여, 고정된 데이터셋과 분리된 현실 세계의 신호를 제공합니다.
실시간 안정성과 품질 모니터링을 위해 자동화된 헬스 체크가 구축되었으며, 에이전틱 플로우(agentic flows)가 올바르게 동작하는지를 검증했습니다.
단순히 상위 API 호출 성공 여부가 아니라, 적절한 서브 에이전트, 도구, 콘텐츠 액션이 정확히 호출되는지를 확인합니다.
이와 더불어 광범위한 신뢰성 모니터링 대시보드와 SLO가 운영되며, 급격한 에러 스파이크와 성능 저하를 감지하는 탐지 시스템도 포함되어 있습니다.
결론
AI를 위한 시스템을 구축하려면 사고방식의 전환이 필요합니다.
업계는 매우 빠르게 변화하고 있으며, 코드·프롬프트·모델 역시 지속적으로 빠르게 진화할 것입니다.
그러나 견고한 평가(evaluation) 체계, 온라인 실험을 위한 정교한 메트릭, 그리고 포괄적인 신뢰성 모니터링이 있어야만 빠른 반복을 안정적으로 수행할 수 있습니다.
Rovo를 활용한 콘텐츠 생성은 새로운 기반 경험이며, 향후 Confluence AI 기능의 핵심 구성 요소로 확장될 것입니다.
이는 시작에 불과합니다.
Claude Code Security와 SonarQube의 역할 구분
AI 코딩 도구의 활용이 빠르게 확산되면서, 이제는 “AI가 코드를 얼마나 잘 작성하는가”뿐 아니라 “AI가 만든 코드를 얼마나 신뢰할 수 있는가”가 중요한 질문이 되고 있습니다.
최근 Anthropic은 Claude Code Security를 발표했습니다. Claude Code Security는 AI 모델을 활용해 코드베이스를 스캔하고, 메모리 손상, 인젝션 결함, 인증 우회와 같은 고위험 취약점을 식별하며, 발견된 이슈에 대한 패치까지 생성하는 research preview 형태의 도구입니다.
SonarSource는 이 도구를 기존 보안 도구를 대체하는 솔루션이라기보다, AI 기반 보안 연구자에 가까운 개념으로 설명합니다.
즉, 모든 코드를 체계적으로 검증하는 도구가 아니라, 기존 도구가 놓칠 수 있는 복잡하고 중요한 취약점을 탐색하는 보완적 역할에 가깝다는 것입니다.
Claude Code Security는 무엇인가요?
Claude Code Security는 Anthropic 에서 개발한 연구용 프리뷰 버전 으로, AI 모델을 사용하여 코드베이스를 스캔하고 메모리 손상, 인젝션 결함, 인증 우회와 같은 심각도가 높은 특정 취약점을 식별하고 발견된 문제를 패치합니다.
SonarSource는 Anthropic이 발표한 내용은 에이전트형 보안 연구원과 유사하다고 말합니다.
보안 연구팀이나 윤리적 해커를 고용하거나 애플리케이션의 취약점을 찾는 버그 바운티 프로그램을 운영하는 등 다양한 기법을 활용하는 것이 오랫동안 최선의 방법으로 여겨져 왔습니다.
이러한 접근 방식은 SAST 및 DAST를 포함한 다른 사이버 방어 체계를 보완하여 일반적으로 간과되는 문제를 찾아냅니다.
Claude Code Security는 메모리 손상, 인젝션 취약점, 인증 우회, 복잡한 논리 오류 등 패턴 매칭 도구가 일반적으로 놓치는 심각도가 높은 취약점에 집중합니다.
일단 문제를 발견하면, 적대적 검증이라는 기술을 사용하여 문제가 실제로 존재하는지 확인한 다음, 식별된 문제를 해결하기 위한 패치를 생성합니다.
에이전트 기반 보안 연구는 코드베이스 및 애플리케이션 보안을 전반적으로 개선하는 데 큰 가능성을 보여줍니다.
보안 연구원들의 노력을 증폭시키고 ( 현재 베타 버전으로 제공되는 SonarQube Remediation Agent 와 유사하게 ) 문제 해결의 마지막 단계를 해결함으로써 시너지 효과를 창출합니다.
기존 기술과 함께 사용하면 더욱 건전하고 안전한 코드베이스를 구축할 수 있을 것으로 기대합니다.
Anthropic은 제품 설명에서 "Claude Code Security는 기존 도구가 놓칠 수 있는 부분을 찾아내고 문제 해결의 고리를 완성함으로써 기존 도구를 보완합니다."라고 설명합니다.
SonarQube와 Claude Code Security의 역할은 무엇가요?
- SonarQube는 모든 코드를 체계적으로 평가합니다.
반면, Claude Code Security는 샘플링 기반의 부분 검사 방식을 사용합니다.
- SonarQube는 정의된 문제 세트를 일관되고 반복적으로 평가하여 검토가 완료되었음을 보장합니다.
반면, Claude Code Security는 전체 코드에 대한 일관된 검증보다는, 발견 가능성이 있는 고위험 취약점을 찾아내는 탐색형 접근에 가깝습니다.
- SonarQube는 단순한 패턴 매칭을 넘어 데이터 흐름과 같은 복잡한 문제를 평가하는 정교한 수학적 추론 기법을 사용합니다. 이 모든 것을 업계 최저 수준의 오탐률(false positive rate)을 유지하면서 구현합니다.
반면 Claude Code Security는 오류에 취약한 확률적 추론 기법을 사용하고, 토큰 소모가 심하고 편향적이며 신뢰도가 낮은 LLM 기반 검증 기법을 사용합니다.
즉, 두 도구는 매우 다르지만 상호 보완적인 역할을 합니다.
- SonarQube: 엄격하고 일관성 있으며 빠르고 저렴한 코드 검토 및 검증
- Claude Code Security: 드물지만 가치가 높은 취약점을 찾아내는 기회주의적 접근 방식.
SonarQube의 접근 방식은 모든 코드 라인이 신뢰성과 유지 관리성에 대한 정의된 표준을 충족하도록 보장하는 동시에 오픈 소스 종속성에 대한 알려진 취약점 및 라이선스 위험을 모니터링합니다.
이 방법론은 결정론적이고 일관성이 있습니다. 동일한 코드를 입력하면 매번 동일한 결과가 나옵니다. 또한 포괄적입니다. 코드베이스 전체를 검사하며, 특정 부분만 선별적으로 검사하는 것이 아닙니다.
마지막으로, 설명이 가능합니다. 문제가 발생하면 어떤 규칙이 어떤 이유로 적용되었는지 정확하게 확인할 수 있습니다.
이는 몇 가지 실질적인 이유로 중요합니다.
- 감사자와 규정 준수 체계는 코드 점검이 이루어졌다는 일관되고 반복 가능한 증거를 요구합니다.
- 개발팀은 코드 병합 전에 IDE 내에서, CI/CD 파이프라인의 일부로, 일반적인 워크플로에서 바로 활용할 수 있는 결과를 필요로 합니다.
- 보안 범위는 자체 코드뿐만 아니라 오픈 소스 종속성, 인프라 구성, 그리고 실수로 커밋되었을 수 있는 기밀 정보까지 포함해야 합니다.
두 도구의 차이
| 구분 | SonarQube | Claude Code Security |
|---|---|---|
| 주요 목적 | 체계적인 코드 검증 및 리뷰 | 스팟 체크와 취약점 발견 |
| 분석 범위 | 전체 코드베이스, 모든 코드 라인, 매 스캔 | 기회주의적 접근, 포괄적 검증 보장 아님 |
| 일관성 | 결정론적. 같은 코드에 같은 결과 | 확률적. 실행마다 결과가 달라질 수 있음 |
| 오탐률 | 약 3%로 제시 | 알려지지 않음. LLM은 오탐을 낼 수 있음 |
| 설명 가능성 | 각 발견 사항에 명확한 룰 참조 제공 | AI 추론 기반으로 감사가 어려울 수 있음 |
| 컴플라이언스 활용 | 감사자와 규제기관에 수용 가능한 근거 제공 | 현재 단독 컴플라이언스 근거로는 적합하지 않음 |
| 속도와 비용 | 빠르고 예측 가능한 비용 | 느리고 토큰 소비가 큼 |
| 도입 현황 | 700만 명 이상 사용자, CI/CD 워크플로우 및 주요 AI 코딩 도구와 통합 | 현재 research preview, Claude Code에서만 사용 가능 |
보안 체계는 하나의 도구만으로 완성되지 않는다
보안에 가장 민감한 조직들은 다양한 도구 포트폴리오에 의존합니다. 일반적인 성숙한 보안 관행은 이미 여러 계층의 방어 체계를 결합하고 있는데, 단 하나의 방법으로는 모든 것을 차단할 수 없기 때문입니다
대표적인 계층은 다음과 같습니다.
- 개발 워크플로우에 통합된 자동화 코드 분석
SAST, SCA, secrets, IaC 분석 등이 여기에 포함됩니다. - 특정 취약점 유형을 위한 전용 보안 테스트 도구
- 아키텍처와 설계를 검토하는 내부 보안팀
- 기존 체계가 놓친 문제를 찾는 외부 보안 연구자 또는 버그 바운티 프로그램
SonarSource는 Claude Code Security가 이 중 네 번째 범주에 자연스럽게 들어간다고 설명합니다. 즉, AI 기반 보안 연구자로서 코드베이스를 대상으로 잠재적인 취약점을 선제적으로 탐색하는 역할입니다.
따라서 중요한 질문은 “어떤 도구를 사용할 것인가”가 아니라, “각 보안 계층이 무엇을 커버하고 있으며, 어디에 공백이 있는가”입니다.
애플리케이션 보안의 다음 진화 단계
AI 기반 보안 리서치 도구의 등장은 업계에 긍정적인 변화입니다.
맥락적 추론이 필요한 취약점, 즉 특정 코드가 원래 어떤 동작을 해야 하는지 이해하고, 그 의도가 어디에서 깨지는지를 찾아내는 작업은 그동안 숙련된 보안 연구자의 영역에 가까웠습니다.
이러한 역량을 더 쉽게 활용하고, 더 넓은 범위로 확장할 수 있게 만드는 것은 분명 가치 있는 일입니다.
다만. AI 리서치 도구를 흥미롭게 만드는 특징은 동시에, 이 도구들이 체계적인 코드베이스 분석을 대체하기에는 적합하지 않은 이유이기도 합니다.
AI 리서치 도구는 모든 것을 빠짐없이 검사하지 않습니다. 실행할 때마다 항상 같은 결과를 보장하지도 않습니다. 또한 컴플라이언스 프레임워크가 요구하는 구조화되고 감사 가능한 증거를 제공하지도 못합니다.
앞으로의 애플리케이션 보안은 이 두 계층이 함께 강화되는 방향으로 발전할 가능성이 높습니다. 결정론적이고 포괄적인 스캐닝은 검증 계층을 담당합니다.
즉, 알려진 모든 유형의 취약점이 전체 코드에 걸쳐 지속적으로 확인되었는지를 보장하는 역할입니다. 반면 AI 보조 리서치는 탐색 계층을 담당합니다. 규칙만으로는 미리 예측하기 어려운 문제를 찾아내는 역할입니다.
이 두 접근 방식은 함께 사용될 때, 어느 한쪽만 사용할 때보다 더 넓은 보안 범위를 다룰 수 있습니다.
Claude Code Security는 스팟 체크 도구입니다.
SonarQube는 포괄적인 감사 및 검증 플랫폼입니다.
각 도구에는 각자의 역할이 있습니다.
요약:
SonarQube의 체계적인 코드베이스 분석은 SAST, SCA, 시크릿, IaC를 포함하며, 수학적 추론을 활용해 전체 코드베이스에 대해 포괄적이고 일관되며 감사 가능한 커버리지를 제공합니다.
이는 보안 실무 기반이 됩니다. AI 보조 보안 리서치는 규칙만으로는 예측하기 어려운, 특정 맥락에 따라 발생하는 취약점을 찾아냅니다. 이는 지금까지 인간 보안 연구자와 버그 바운티 프로그램이 수행해 온 역할과 같습니다.
따라서 이 두 역량은 경쟁 관계가 아니라 상호 보완 관계입니다. 가장 강력한 보안 체계는 두 가지를 함께 활용하는 것입니다.
컴플라이언스 요구사항, 규제 의무, 또는 일관된 보안 커버리지를 입증해야 하는 팀에게는 체계적인 코드 분석이 여전히 필수적입니다. 그리고 이는 research preview 단계의 도구로 대체될 수 없습니다.
Anthropic은 실제로 유용한 도구를 만들었습니다. 다만 이 도구의 효과를 가장 크게 얻을 수 있는 팀은 이미 탄탄한 체계적 코드 분석 기반을 갖춘 팀이라고 볼 수 있습니다.
바로 그 기반이 있어야 AI 보조 리서치가 가장 효과적으로 작동하는 데 필요한 맥락을 제공할 수 있기 때문입니다.
출처: SonarSource, “Thoughts on Claude Code Security” by Manish Kapur
https://www.sonarsource.com/blog/thoughts-on-claude-code-security/