
목차
Rovo 검색
오늘날 팀은 수많은 툴과 애플리케이션에서 정보를 다루고 있습니다.
Confluence, Jira 같은 Atlassian 제품부터 Google Drive, Slack, SharePoint 등 외부 SaaS까지—데이터는 여기저기 흩어져 있죠.
Rovo 검색은 이러한 복잡성을 단순화해, 빠르고 관련성 높은 검색 결과를 제공하는 통합 솔루션입니다.
이번 블로그에서는 Rovo 검색이 어떻게 작동하는지, 그리고 왜 관련성(Relevance), 스마트 답변(Smart Answers), 개인화(Personalization)이 중요한지 살펴봅니다.
Rovo 검색이 다루는 영역
Rovo의 목표는 고객이 Confluence, Jira, Bitbucket 같은 Atlassian 제품뿐만 아니라 Google Drive, Slack, SharePoint와 같은 외부 SaaS 애플리케이션까지 검색할 수 있도록 하는 것입니다.
Atlassian 제품: Confluence, Jira, Bitbucket
외부 SaaS: Google Drive, Slack, SharePoint 등
현재 Rovo는 50개 이상의 SaaS 애플리케이션에 대해 엔터프라이즈 검색을 지원합니다.
이때 각 SaaS를 Rovo와 연결해주는 기술을 커넥터(connector)라고 부릅니다.
더 많은 정보는 Available Rovo Connectors | Atlassian.에서 확인할 수 있습니다.
왜 검색 인프라가 중요한가?
검색은 단순히 정보를 찾는 기능을 넘어, Rovo의 모든 인터페이스의 기반이 됩니다.
검색(Search)
챗(Chat)
콘텐츠 생성 에이전트(Content creation agents)
이 모든 기능은 검색 인프라가 가져오는 맥락(Context)에 의존합니다.
그렇기 때문에 검색 인프라와 검색 관련성은 Rovo의 근간을 이루는 핵심 블록으로 여겨집니다.
이번 블로그에서 다룰 주제
검색 관련성 스택(Search Relevance Stack)
스마트 답변(Smart Answers)
개인화 기법(Personalization techniques)
콘텐츠가 색인되는 과정도 간략히 언급하겠지만, 이번 글에서는 주로 이미 색인된 콘텐츠가 어떻게 관련성 있는 결과로 반환되는지에 집중합니다.
주요 용어 정리 (Terminologies)
본격적으로 Rovo 검색의 작동 방식을 설명하기 전에, 이 블로그에서 반복적으로 사용될 몇 가지 개념을 먼저 정리하고 가겠습니다.
Connector (커넥터)
커넥터는 외부 SaaS 애플리케이션이나 데이터 소스를 Rovo와 연결하는 통합 기능입니다.
예: Google Drive 커넥터, SharePoint 커넥터 등.
OpenSearch
콘텐츠를 색인화(indexing)하고 검색할 수 있도록 하는 플랫폼입니다. Atlassian은 현재 AWS OpenSearch를 사용하고 있습니다.
모든 콘텐츠는 OpenSearch에서 “문서(document)”로 저장되며, 여기에는 텍스트와 메타데이터가 포함됩니다. 이 속성들은 필요에 따라 검색 가능하도록 설정할 수 있습니다.
BM25 (Best Match 25)
검색 엔진에서 사용되는 랭킹 함수(ranking function)로, 특정 검색 질의(query)에 대해 문서가 얼마나 관련성이 있는지를 계산하는 방식입니다.
KNN (K Nearest Neighbors)
질의와 가장 가까운 문서들을 의미적 유사성(semantic similarity)에 기반해 찾아내는 알고리즘입니다.
Rovo의 의미 기반 검색(semantic search) 기능은 이 기법을 활용합니다.
LLM (Large Language Model, 대규모 언어 모델)
Atlassian은 여러 가지 대규모 언어 모델을 활용하여 검색과 답변 생성을 지원합니다.
검색 경험 (Search Experiences)
Rovo에서는 여러 가지 검색 경험을 제공하며, 이는 다음 섹션에서 설명합니다.
빠른 찾기 (Quick Find)
Atlassian 제품 상단에 위치한 검색창을 의미합니다.
이 기능은 여러 진입 지점에서 지원되며, 예를 들어 Home, Confluence, Jira 등이 있습니다.
전체 검색 (필터 지원 고급 검색)
빠른 찾기(Quick Find)에서 엔터를 누르면 고급 전체 검색 경험으로 이동하게 됩니다.
이 모드에서는 제품, 유형, 작성자, 시간 등 다양한 필터를 활용할 수 있습니다.

이 기능은 더 깊이 있는 검색을 수행하여 관련성 있고, 신뢰할 수 있으며, 인기 있는 결과 그리고 사용자가 선호하는 제품의 결과를 보여줍니다.
빠른 찾기(Quick Find)와 달리, 단순히 사용자의 최근 활동만을 기반으로 콘텐츠를 가져오지는 않습니다.
다만 최근 활동은 여전히 더 관련성 높은 결과를 목록 상단에 유지하는 데 도움을 줍니다.
스마트 답변과 출처 표시 (Smart Answers with citations)
검색에서의 스마트 답변은 사용자의 질문에 대해 빠르고 AI 기반의 답변을 제공하도록 설계되어 있습니다.
이 답변은 연결된 지식 베이스 전반에서 가져온 신뢰할 수 있는 콘텐츠를 기반으로 합니다.
신뢰성과 사용자 신뢰를 보장하기 위해, 스마트 답변에는 각 답변을 생성하는 데 사용된 정확한 출처(citations)가 함께 제공됩니다.


스마트 답변은 특정 의도 카테고리에 대해서는 간결한 지식 카드(knowledge cards)를 함께 보여줄 수도 있습니다.

Rovo Chat
검색은 Rovo Chat을 뒷받침하는 핵심 도구 중 하나로, AI 어시스턴트가 사용자의 질문에 적합한 결과를 생성할 수 있도록 합니다.
Rovo Chat의 검색 기능은 스마트 답변(Smart Answers) 경험과 동일한 기본 인프라에 의해 구동됩니다.

50+개 이상의 SaaS 애플리케이션에서 검색하는 방식
다양한 콘텐츠 플랫폼과의 통합 방식을 지원합니다.
1. 전체/대부분 콘텐츠 색인 (Full Ingestion)
많은 애플리케이션의 경우, 해당 플랫폼의 전체 또는 대부분의 콘텐츠를 Rovo 검색 색인에 직접 수집합니다.
→ 이렇게 하면 풍부하고 관련성 높은 검색 경험을 제공할 수 있습니다.
예: Google Drive, Slack
2. 링크 기반 색인 (Linked Content Ingestion)
일부 애플리케이션은 Rovo의 1st-party 제품(예: Confluence, Jira)에 링크된 콘텐츠를 색인합니다.
→ 이를 통해 Confluence나 Jira에 최근 연결된 서드파티 콘텐츠도, 해당 1st-party 콘텐츠를 볼 수 있는 사용자라면 Rovo에서 검색할 수 있습니다.
예: Figma
3. 연합 검색 (Federated Search)
소수의 애플리케이션은 서드파티 검색 API와 직접 연동하여 검색을 수행합니다.
→ 이 방식으로도 Rovo는 여전히 원스톱 검색 솔루션 역할을 합니다.
예: Gmail, Outlook Mail
4. 사용자 활동 신호 반영
Google Drive, SharePoint 같은 완전 색인(fully ingested) 플랫폼에서는 사용자 활동 신호를 수집합니다.
→ 이를 활용해 검색 결과의 랭킹을 더 정교하게 조정할 수 있습니다.
5. 다양한 검색 스택 (Search Stacks)
Rovo는 50개 이상의 제품을 확장성 있게 지원하기 위해 여러 검색 스택을 운영합니다.
문서 검색 스택(Document Search Stack) → 지식 베이스 형태의 콘텐츠에 특화
메시징 검색 스택(Messaging Search Stack) → 메시지 기반 콘텐츠 전용
기본 스택(Default Stack) → 디자인, 비디오, 표 등 다양한 기타 콘텐츠 유형 지원
검색 작동 방식
검색 요청의 전체적인 흐름은 다음과 같습니다:
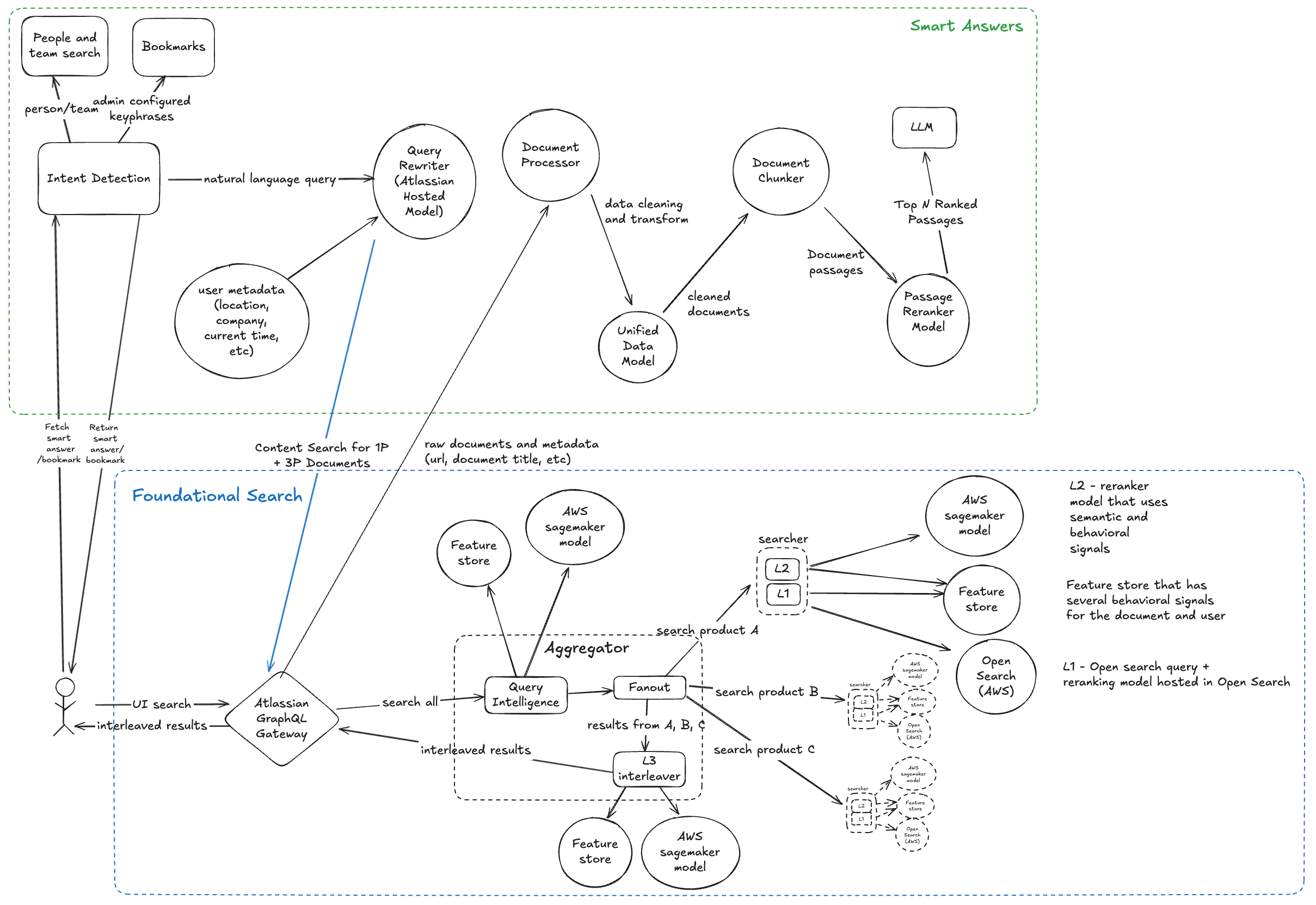
전반적인 흐름에는 두 가지 주요 구성 요소가 있습니다.
기본 검색 (Foundational Search)
기본 검색 흐름은 모든 콘텐츠 검색의 핵심이 되는 단계입니다.
Rovo의 검색 스택은 여러 계층으로 구성되어 있으며, 각 단계에서 점점 더 정교하게 결과를 다듬습니다.
1. 쿼리 인텔리전스 (Query Intelligence)
검색 스택의 첫 번째 계층으로, 사용자의 의도를 이해하는 단계입니다.
자연어 쿼리 이해 (예: “휴가 규정 알려줘”)
제품/콘텐츠 유형 식별 (예: Jira 이슈인지, Confluence 페이지인지)
철자 오류, 오타, 약어 보정
쿼리 재작성(Query rewriting)
이를 위해 사전 학습된 언어 모델을 활용해 분류(classification)를 수행하고, 자체 호스팅 LLM으로 쿼리를 재구성합니다.
2. OpenSearch Retriever L1
두 번째 계층에서는 OpenSearch 기반 쿼리를 실행합니다.
BM25 및 KNN 기법을 사용하여 텍스트 질의를 색인된 콘텐츠와 매칭
권한(permission) 체크 및 필터 적용
리스코어링(Rescoring) 단계에서 문서의 인기 여부, 기여자 등 인덱스 수준 특징을 반영해 재랭킹
여기에는 Gradient Boosted Decision Tree(GBDT) 모델을 OpenSearch에 직접 호스팅하여 재랭킹에 활용합니다.
3. Semantic & Behavioral Ranker L2
세 번째 계층에서는 OpenSearch가 반환한 결과를 더 풍부한 의미적 관련성(semantic relevance)과 행동 신호(behavioral signals)를 기반으로 재정렬합니다.
피처 스토어(Feature Store)에서 신호를 가져와 AWS SageMaker에 호스팅된 재랭킹 모델 실행
자체 파인튜닝한 크로스 인코더(cross-encoder) 모델로 의미적 관련성을 평가
DCN(Deep & Cross Network) 모델로 사용자 행동 신호(클릭, 참여도 등)를 반영
L2 Ranker는 멀티태스크 방식으로 학습되어, semantic relevance score, pCTR(예상 클릭률) 등 여러 점수를 산출합니다.
이 점수들을 얕은 레이어(shallow layer)에서 종합하여 최종 랭킹 점수를 만듭니다. 이 과정은 항상 검색 성공률을 높이면서도 관련성을 보장하도록 최적화되어 있습니다.
4. Interleaver L3
마지막 단계에서는 L2 단계를 거친 뒤, 여러 제품에서 가져온 결과를 최종적으로 섞어(interleave) 최종 목록을 생성합니다.
제품 선호도(product affinity)
쿼리와 텍스트 콘텐츠 간의 의미적 관련성
이 기준들을 종합해 최종 검색 결과 리스트가 완성됩니다.

검색 요청이 처리되는 방식
사용자가 검색 요청을 실행하면, 프론트엔드는 GraphQL 검색 엔드포인트를 호출합니다.
이 엔드포인트는 Aggregator라는 서비스에 위치해 있으며, 여기서 쿼리 인텔리전스(Query Intelligence)를 수행하고 다양한 제품으로 검색 쿼리를 분산(fan-out)하는 역할을 합니다.
우리는 모든 제품을 지원하기 위해 여러 개의 인덱스를 운영하며, 이를 병렬 처리하여 지연 시간을 줄이고 인덱스 매핑을 효율적으로 관리합니다.
1. 쿼리 인텔리전스
사용자의 질의는 재작성/재구성 과정을 거쳐 의미가 명확해진 뒤, 다음 단계로 전달됩니다.
2. Fan-out → Searcher 서비스
쿼리는 각 제품별 검색 요청으로 분산되며, 이 요청은 Searcher라는 또 다른 서비스로 전달됩니다.
Searcher 서비스는 AWS OpenSearch와 직접 통신하며, 콘텐츠 검색을 담당합니다.
Searcher에는 두 가지 계층이 있습니다:
L1 (콘텐츠 검색): 사용자 권한을 반영한 콘텐츠 검색
L2 (재랭킹): 앞서 설명한 의미적·행동적 신호 기반의 재정렬
3. 보안 강화 – 권한 확인
재랭킹 이후에는 1st-party 또는 3rd-party 제품과의 추가 권한 확인을 수행합니다.
→ 이를 통해 보안 수준을 강화하고, 사용자가 접근 권한을 가진 콘텐츠만 결과에 노출되도록 보장합니다.
4. 최종 통합 – L3 Ranker
각 제품별 결과가 수집되면, 우리는 다시 한 번 L3 Ranker를 적용하여 다양한 제품의 결과를 최종적으로 통합(interleave) 합니다.
이 단계에서는 제품 선호도(product affinity)와 질의 의도(intent)를 반영해 결과 순서를 결정합니다.
예시:
“search improvements roadmap page”라는 질의는 Confluence 페이지를 우선시
“SEARCH-4356” 같은 질의는 Jira 티켓을 최상위에 배치
스마트 답변 (Smart Answers)
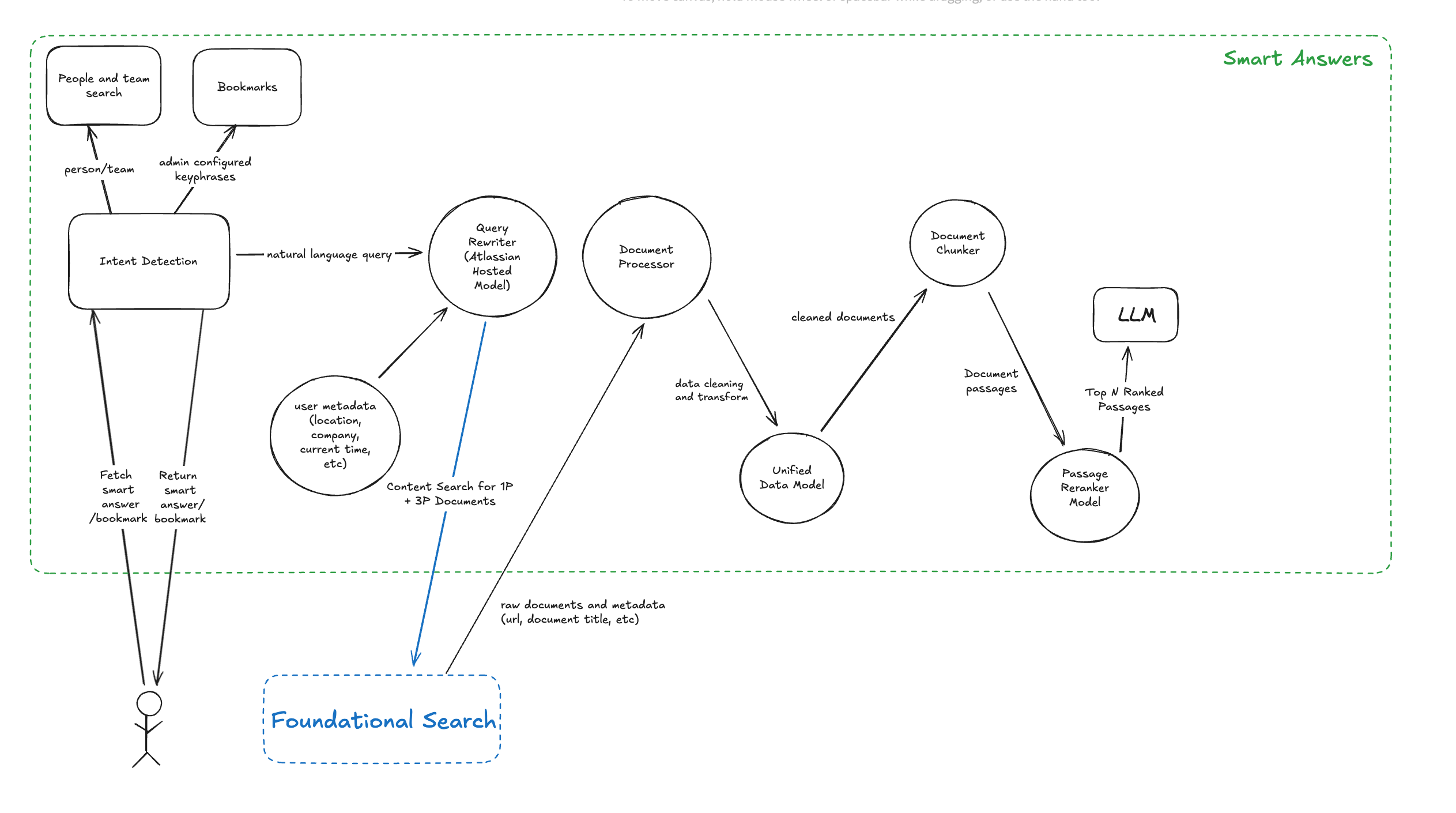
사용자가 쿼리를 입력하면, 먼저 여러 의도(intent) 중 하나로 분류됩니다:
Person (사람) → 사람 엔티티를 식별하고 스마트 카드로 표시
Team (팀) → 팀 엔티티를 식별하고 스마트 카드로 표시
Bookmarks (북마크) → 조직 관리자가 저장해둔 북마크 링크를 바로 반환
Natural Language (자연어) → 스마트 답변(Smart Answer) 워크플로우 실행
None (없음) → 스마트 답변은 표시되지 않고 일반 검색 결과 페이지 제공
처음 세 가지 쿼리 카테고리는 탐색 속도를 높이기 위해 거의 즉시 답변을 제공합니다. 반면, 자연어 쿼리 카테고리는 스마트 답변 워크플로우 전체를 실행해야 합니다.
스마트 답변 워크플로우 (Smart Answer Workflow)
쿼리가 자연어 질의(Natural Language Query)로 분류되면, 검색 툴로 전달됩니다.
이때 검색 툴은 Atlassian이 자체 호스팅하는 쿼리 재작성(query rewrite) 모델을 활용해 원래 질의를 다시 작성합니다.
이 과정은 사용자의 입력을 검색 관련성에 최적화하기 위함입니다.
1. 쿼리 재작성 (Query Rewriting)
쿼리를 재작성하기 전에, 우리는 사용자별 맥락 정보(조직, 위치, 현재 시간 등)를 쿼리 리라이터에 추가로 제공합니다.
예: “when is the next holiday” → “when is the next holiday in the US”
이렇게 하면 쿼리에 더 풍부한 정보를 반영할 수 있습니다.
이 단계에서는 일반적인 Query Intelligence 계층을 우회하여, 맥락 정보를 충분히 활용한 재작성 과정을 거칩니다.
2. GraphQL 검색 서비스
강화된 맥락으로 재작성된 쿼리는 GraphQL 검색 서비스로 전달되어, 기본 검색 스택(Foundational Search Stack)을 통해 검색이 실행됩니다.
3. 데이터 변환 (Data Transformation)
여러 데이터 소스에서 다양한 형태의 문서가 반환되면, 우리는 이를 통합 데이터 모델로 변환합니다.
문서, 동영상 자막, Slack 메시지 등 다양한 커넥터 데이터를 처리 가능
50개 이상의 커넥터를 일관되게 지원하기 위함
4. 문서 청킹 (Document Chunking)
통합된 문서를 작은 단위(passage snippets)로 나눕니다.
이렇게 나눈 청크들을 cross-encoder 모델(ms-marco-MiniLM 등)로 평가
이 과정에서 가장 관련성 높은 청크를 추려내어 답변 생성에 활용
5. 출처 표기 (Citations)
문서를 청킹할 때, 각 단위에 페이지 수준 메타데이터(URL, 문서 제목)를 함께 부여합니다.
LLM이 답변을 생성할 때, 이 메타데이터가 근거(grounding signal) 역할을 함
덕분에 스마트 답변은 생성된 답변 속 각 주장마다 출처를 직접 표시할 수 있음
이는 passage-level citation(단락 단위 출처 표시) 방식으로, 최종 답변의 신뢰성을 크게 높입니다.
검색 관련성
Relevance (검색 관련성)
검색 결과가 의미 있는 결과를 보여주고, 서로 간의 순위가 효과적으로 매겨질 때 이를 ‘관련성 있다’고 합니다.
예를 들어, Google Drive에 최근 업로드된 “Search relevance deep dive” 발표 자료가 있다면, 사용자가 “Search relevance deep dive”를 검색했을 때 그 자료는 최상위에 표시되어야 합니다.
특히 검색자가 직접 발표자이거나 해당 팀에 속해 있다면, 그 자료는 상위 3개 결과 안에 포함되어야 합니다.
물론 다른 콘텐츠들도 ‘검색 관련성’을 다룰 수 있지만, 최신성(recency)과 사용자의 연관성(affinity)에 따라 가장 적절한 자료가 맨 위로 노출되는 것이 이상적인 결과입니다.
Index (색인)
우리는 검색 색인에 콘텐츠, 작성자, 메타데이터를 저장합니다.
메시징 플랫폼의 경우, 관련 메시지를 묶어 더 풍부한 문맥을 제공합니다.
색인에는 인기도(popularity), 권위(authority) 신호도 함께 저장됩니다.
기여자 수
참여도(조회, 댓글, 반응 등)
컨테이너/폴더 유형(개인용 vs 공개용)
사용자 ID, 멘션, 관련 메타데이터도 함께 저장하여, 검색 결과 UI에서 풍부한 정보를 표시할 수 있습니다.
즉, 단순한 의미적·어휘적 매칭을 넘어서 다양한 신호를 종합해 검색 품질을 높이는 것이 색인의 핵심입니다.
Personalization (개인화)
Rovo 검색 결과는 사용자 맞춤화(personalization)가 적용됩니다.
개인화 방식에는 다음과 같은 것들이 있습니다:
사용자가 직접 작성한 콘텐츠는 더 높은 순위에 노출
협업자가 작성한 콘텐츠도 더 높은 순위에 반영
Slack, Teams 같은 메시징 앱에서는 사용자가 최근 활발히 활동한 상위 채널의 결과 우선 표시
콘텐츠 권위를 판단할 때는 컨테이너 유형, 콘텐츠 길이, 기여자 수, 최신성, 활동성 등을 종합 평가
또한:
인기도(Popularity)는 조회수, 좋아요, 댓글 등 다양한 참여 신호로 계산
최신성(Freshness)은 최근 업데이트 시간을 기준으로 하며, 제품마다(일/주/월 단위) 다르게 적용
최신 결과는 상단으로 끌어올리고, 오래된 결과는 점차 가중치를 낮춤
검색 관련성 평가하는 방법
Rovo에서 검색할 때, 사용자는 빠르면서도 가장 관련성 높은 결과를 기대합니다.
하지만 실제로 검색이 잘 작동하는지 어떻게 알 수 있을까요?
Atlassian은 사용자 행동 신호, 명시적 피드백, 언어 모델의 평가를 결합하여 Rovo 검색 결과가 항상 정확하고 유용하도록 관리합니다.
온라인 평가 (Online Evaluation)
우리는 실제 사용자 행동 + 명시적 피드백 + AI 판단을 결합해 온라인 평가를 수행합니다.
이를 통해 검색 결과가 단순히 빠르기만 한 것이 아니라, 정말로 유용한지를 검증합니다. 이런 접근 방식은 신뢰 구축, 생산성 향상, 지식 접근성 보장에 기여합니다.
Query Success Rate (QSR)
Rovo 검색의 핵심 지표로, 사용자가 원하는 답을 얻었는지를 추적합니다.검색 결과 클릭
특정 페이지에 머문 시간
스마트 답변(Smart Answer)에서 직접 답변 획득
사용자가 만족스럽게 검색을 마치면 그것이 곧 성공입니다.
Clicks & Dwell Time
어떤 결과가 클릭되었고, 해당 페이지에 얼마나 오래 머물렀는지를 분석해 실제로 도움이 된 결과를 파악합니다.Explicit Feedback
👍 / 👎 같은 직접적인 피드백을 통해 검색 품질을 개선합니다.
이러한 신호들을 종합해, 검색 결과와 스마트 답변 전반에 대한 종합 성공 점수를 산출합니다.
오프라인 평가 (Offline Evaluation)
온라인 평가만으로는 충분하지 않습니다. 우리는 다양한 쿼리-문서 쌍을 기반으로 오프라인 평가도 수행합니다.
데이터 세트:
성공적인 검색 클릭 기반 쿼리 세트
전문가가 직접 선별한 골든 쿼리 세트
합성(synthetic) 쿼리 세트
이를 통해 “쿼리 Qi → 기대되는 문서 Di”라는 매핑을 확보합니다.
평가 지표
Recall@k: 기대 문서가 상위 k개의 결과 안에 포함되는 비율
NDCG (Normalized Discounted Cumulative Gain): 결과 순위가 얼마나 이상적인 순위와 가까운지를 평가
MRR (Mean Reciprocal Rank): 기대 문서가 얼마나 잘 상위에 위치하는지 평가
LLM-as-a-Judge: 대규모 언어 모델(LLM)을 심사관으로 활용하여 결과 랭킹이 인간의 기대에 부합하는지 평가. 이 데이터는 파인튜닝 학습 세트로도 활용
왜 오프라인 평가가 중요한가?
Rovo를 출시하기 전에는, 아직 고객이 없어 온라인 참여 데이터를 충분히 확보할 수 없었습니다.
또한 Atlassian 직원들도 모든 SaaS 커넥터를 내부적으로 쓰지 않았기 때문에, 새로운 커넥터를 출시할 때는 오프라인 평가가 필수였습니다.
이러한 오프라인 평가는 우리가 개선할 때마다 품질을 어떻게 유지·향상했는지, 기준선 대비 성능이 어떤지를 확인할 수 있는 중요한 수단이었습니다.
앞으로의 여정 (Stay tuned for more)
Rovo 검색은 계속해서 새로운 커넥터를 추가하고 고객의 피드백을 반영하며, 최신 AI 기술을 접목한 혁신적인 업그레이드를 이어가고 있습니다.
검색 관련성 스택(Search Relevance Stack)
실험 프레임워크(Experimentation Framework)
평가 파이프라인(Evaluation Pipeline)
이 모든 요소가 Rovo의 성공을 가능하게 한 핵심 기반입니다. 앞으로도 더 원활하고 강력한 검색 경험을 제공할 Rovo를 기대해 주세요.
지금 바로 Rovo를 사용해, GenAI로 조직의 지식을 열어보세요.
출처
Unraveling Rovo search relevance - Work Life by Atlassian