출처: Deep Research v2: Inside Atlassian’s Next-Gen AI Research Engine - Work Life by Atlassian
작성자: Xincheng You 외 Atlassian Machine Learning & Engineering Team
발행일: 2025년 12월 17일
AI로 재정의하는 자동화 리서치
2024년 6월 Atlassian은 Rovo Deep Research를 처음 선보이며 하나의 방향성을 제시했습니다.
SaaS와 Atlassian 전반에 흩어진 정보를 연결해, 인용 가능한 임원급 리포트를 몇 분 안에 생성하는 AI 리서처를 제공하겠다는 것이었습니다.
이후 Deep Research는 단순 요약을 넘어 전략 수립 리스크 분석 프로세스 개선처럼 의사결정 난도가 높은 질문에 활용되기 시작했습니다.
사용 사례가 확대되면서, 기존 접근 방식에서 개선이 필요한 지점 또한 점차 분명해졌습니다.
Deep Research v2는 이러한 관찰을 바탕으로 사람이 실제로 조사하는 방식에 더 가까운 리서치 엔진으로 설계되었습니다.
What’s New?
실제 업무 환경에서 Deep Research를 평가한 결과, 몇 가지 공통적인 패턴이 확인되었습니다.
리포트는 기술적으로 정확했지만, 깊이가 충분하지 않거나 맥락과 다른 관점을 충분히 반영하지 못한 경우가 있었습니다.
또한 단 한 번의 실행으로 끝나는 fire-and-forget(실행 후 무시) 방식의 워크플로우는, 초기 리서치 계획이 적절하지 않을 경우 과정 중 이를 조정하기 어렵다는 한계를 드러냈습니다.
Deep Research v2에서는 이러한 문제를 해결하기 위해 워크플로우가 재설계되었습니다.
새로운 증거가 나타날 때마다 반복적으로 탐색·종합·수정하는 흐름이 반영되었으며, 다중 턴 인터랙션을 통해 사용자가 리서치 과정에 보다 적극적으로 개입할 수 있도록 개선되었습니다.
질문 한번으로는 부족한 리서치
“우리 AI 전략의 리스크는 무엇인가요?”
“사고 대응 프로세스의 가장 큰 공백은 무엇인가요?”
이와 같은 질문은 범위가 넓어, 실제 리서치에서는 추가적인 확인이 필요합니다.
어떤 제품을 대상으로 하는지, 어떤 기간을 의미하는지, 누구를 위한 결과물인지를 명확히 해야 합니다.
Deep Research v2에서는 이 단계를 워크플로우에 명시적으로 포함했습니다.
리서치 시작 전 범위, 제약 조건, 성공 기준을 명확히 하는 질문을 먼저 제시함으로써 결과가 사용자의 실제 관심사에 보다 정확히 맞춰지도록 했습니다.
V1 워크플로우의 구조적 한계
기존 v1 워크플로우는 사실상 fire-and-forget 구조였습니다.
초기 계획이 잘못 설정될 경우 결과를 끝까지 기다린 뒤 처음부터 다시 시작해야 하는 상황이 발생했습니다.
v2에서는 리서치 계획 자체가 공유 가능한 산출물로 다뤄집니다.
구조화된 리서치 플랜 제안
섹션, 우선순위, 관점 수정
승인 이후 본격적인 리서치 실행
이를 통해 리서치 초기 단계에서 방향을 조정할 수 있게 되었고, 불필요한 재작업이 크게 줄어들었습니다.
통찰력 및 심층성이 부족한 리포트
기존 리포트는 사실 전달에는 충실했지만, 비교, 맥락, 리스크, 의사결정 포인트가 충분히 드러나지 않은 경우가 있었습니다.
Deep Research v2는 단순한 정보 요약을 목표로 하지 않습니다.
질문에 답하는 것을 넘어 다음에 무엇을 해야 하는지를 고민하게 만드는 리포트를 지향합니다.
이를 위해 더 깊은 탐색, 관점 비교, 패턴 분석, 그리고 실행 가능한 권고안 도출에 초점을 맞추도록 설계되었습니다.
내부 지식 활용의 한계
전략 수립, 시장 분석, 기술 평가는 내부 문서만으로는 충분하지 않은 경우가 많습니다.
공개 리서치, 벤더 문서, 업계 뉴스와 같은 외부 정보가 함께 고려되어야 합니다.
Deep Research v2는 Atlassian 데이터와 연결된 SaaS 정보뿐 아니라, 필요에 따라 퍼블릭 웹 정보까지 함께 활용할 수 있도록 확장되었습니다.
이를 통해 내부 맥락과 외부 시그널이 결합된 엔드투엔드 리서치가 가능해졌습니다.
새로운 아키텍처
Deep Research v2의 핵심에는 대규모 언어 모델(LLM)의 추론 능력을 활용하는 중앙 오케스트레이터 에이전트가 있습니다.
기존 세대의 획일적이고 경직된 파이프라인을 넘어, 상황에 따라 유연하게 대응하는 적응형 지능(Adaptive Intelligence) 기반 구조가 도입되었습니다.
오케스트레이터는 전체 대화 맥락 속에서 각 질문을 분석한 뒤, 복잡도에 따라 즉각적인 응답 또는 다단계·반복적 리서치 프로세스를 실행합니다.
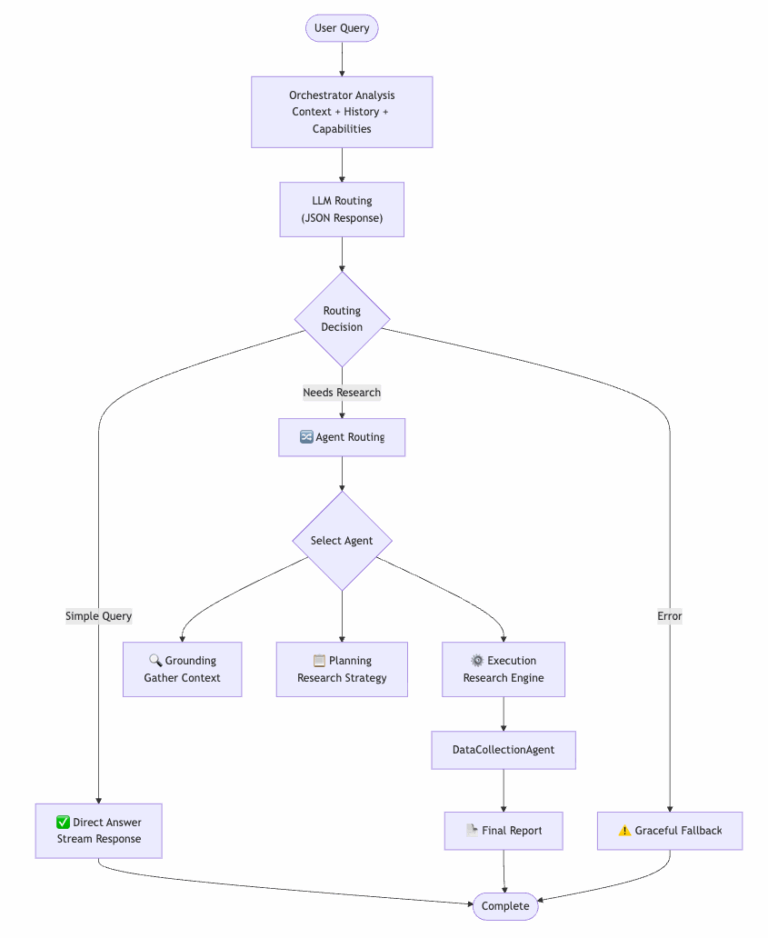
Adaptive Orchestration: 쿼리에서 리포트까지
시스템의 중심에는 오케스트레이터 에이전트가 위치합니다.
오케스트레이터는 사용자 맥락, 대화 이력, 전문 에이전트의 역량을 포함한 동적 프롬프트를 구성합니다.
이를 바탕으로 직접 답변할지, 전문 에이전트에게 위임할지를 판단하는 구조화된 판단 결과가 생성됩니다.
이러한 맥락 기반 라우팅을 통해 단순한 질문에는 빠른 응답이 제공되고 복잡한 요청에는 깊이 있는 분석과 다각적 관점이 적용됩니다.
전문 에이전트와 반복적 리서치
복잡한 리서치 작업은 세 가지 전문 에이전트로 분리됩니다.
Grounding Agent
사용자 환경과 맥락을 파악하고 명확화 질문을 생성Planning Agent
리서치 목표를 구조화된 계획으로 변환Execution Agent
실제 리서치 수행과 반복 개선 담당
특히 Execution Agent에는 v2의 핵심 기술이 집약되어 있습니다.
Execution Agent의 주요 혁신
Self-Evolution Engine: 발견된 정보에 따라 쿼리를 진화시키고 종료 시점을 판단
Dynamic Outline Optimization: 새로운 증거에 맞춰 리포트 구조를 재정렬
Memory Bank Writing: 모든 주장과 섹션별 출처를 저장해 추적성 확보
Test-Time Diffusion: 초안을 노이즈로 간주하고 집중 리서치를 통해 정제
그 결과 모든 문장이 출처로 연결되는 감사 가능한 리포트가 생성됩니다.
성능, 확장성, 안정성
Deep Research v2는 병렬 쿼리 실행을 통해 처리 속도를 향상시키는 동시에 모든 주장에 대한 출처 추적을 가능하게 해 투명성과 신뢰성을 확보합니다.
구성 가능성과 관측성
모델 선택, 실행 파라미터, 기능 플래그를 코드 변경 없이 조정할 수 있어 A/B 테스트, 단계적 롤아웃, 사용 맥락에 따른 최적화를 효과적으로 지원합니다.
또한 구조화된 로그, 지연 시간 지표, 토큰 사용량 모니터링을 통해 시스템 동작을 세밀하게 추적할 수 있도록 설계되었습니다.
비동기 실행과 복구 가능한 스트리밍
Deep Research 작업은 실행 시간이 길고 연산량이 큰 경우가 많습니다.
이에 따라 v2에서는 메인 웹 요청 경로에서 분리된 비동기 실행 구조가 도입되었습니다.
웹 서버는 작업을 백그라운드 워커 풀로 전달하고 진행 상황만 스트리밍 형태로 전달합니다.
이를 통해 사용자 경험은 실시간처럼 유지되며 리서치 엔진은 백그라운드에서 모든 과정을 수행합니다.
전용 워커 플릿을 통해 웹 서버 자원 점유를 방지하고 요청 급증 상황에서도 전체 시스템 안정성을 유지할 수 있도록 설계되었습니다.
또한 재연결 가능한 스트리밍을 지원해 네트워크 오류나 기기 전환 상황에서도 동일한 리서치 세션을 이어갈 수 있습니다.
평가 전략과 결과
I. Reference 기반 평가 전략
RACE 프레임워크 기반 평가(details)
Deep Research의 실제 활용 성능을 평가하기 위해, 장문 리서치 평가에 특화된 RACE 프레임워크를 주요 기준으로 활용하고 있습니다.
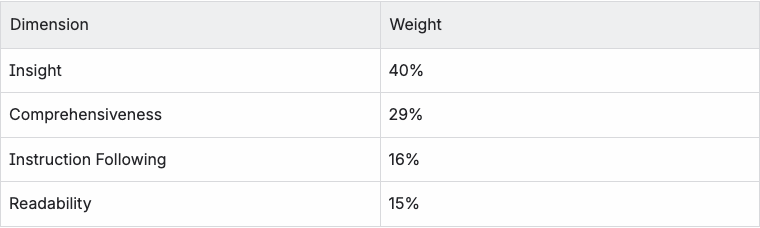
RACE는 각 리포트를 다음 네 가지 관점에서 평가합니다.
Comprehensiveness
리포트가 주제의 핵심 영역을 충분히 다루고 있는지, 주요 내용이 누락되지 않았는지를 평가합니다.Insight
단순한 사실 나열을 넘어 원인, 영향, 트렌드를 분석하고 의미 있는 시사점을 제공하는지를 평가합니다.Instruction Following
리서치 브리프를 얼마나 충실히 따르고, 사용자의 질문에 직접적으로 답하고 있는지를 측정합니다.Readability
구조가 명확하고 논리 흐름이 자연스러워 이해관계자가 쉽게 내용을 소화할 수 있는지를 평가합니다.
RACE의 핵심적인 특징은 단일한 고정 평가 기준을 적용하지 않는다는 점입니다.
질의의 성격에 따라 과제별 가중치와 세부 평가 기준을 동적으로 생성해, 해당 작업에서 “좋은 결과”가 무엇인지를 상황에 맞게 정의합니다.
질의별 가중치 및 평가 기준 예시
다음과 같은 질의를 예로 들 수 있습니다.
“AI와의 상호작용이 인간의 대인관계에 어떤 영향을 미치는지를 논의하시오.
특히 AI가 개인들이 서로 관계를 맺는 방식과 그 이유를 근본적으로 어떻게 변화시킬 수 있는지를 고려하시오.
이 과제에 대해 RACE는 평가 항목별로 서로 다른 가중치를 부여합니다.
아래는 Insight(40%) 항목에 대해 RACE가 생성한 세부 평가 기준(rubric)의 예시입니다.

벤치마크 구성
Deep Research는 공개 벤치마크와 내부 벤치마크를 함께 활용해 평가됩니다.
이를 통해 개방적이고 경쟁적인 환경에서의 성능과, 실제 엔터프라이즈 업무 흐름에서의 활용성을 동시에 검증합니다.
공개 벤치마크 – DeepResearch Bench
DeepResearch Bench는 딥 리서치 시스템 평가를 위해 설계된 공개 벤치마크입니다.
도메인 전문가가 작성한 100개의 박사급 연구 과제로 구성되어 있으며, 딥 리서치 제품 간의 공정한 비교를 목표로 합니다.
현재 Deep Research의 점수는 50.74점으로, 리더보드 기준 4위에 해당합니다.
 \
\
내부 벤치마크 – 엔터프라이즈 리포트
엔터프라이즈 환경에서 Deep Research가 실제로 어떻게 사용되는지를 평가하기 위해, 사내 Confluence에 축적된 고품질 리포트 기반 내부 벤치마크를 운영하고 있습니다.
이 리포트들에 역 프롬프트 엔지니어링(reverse prompt engineering)을 적용해, 실제 기업 업무 흐름을 반영한 리서치 질문으로 변환합니다.
이를 통해 Deep Research가 일상적인 엔터프라이즈 의사결정 과정에서 요구되는 리서치 과제를 얼마나 잘 수행하는지를 평가합니다.
대표적인 활용 사례
시장 및 경쟁 분석
예: “FY25 Q4 기준, 주목해야 할 시장 및 인재 트렌드는 무엇이며 이러한 변화가 채용 및 비즈니스 전략에 어떤 영향을 미칠 수 있는가?”분기 및 임원 보고용 요약
예: “FY26 Q1 ‘State of Atlassian’을 종합적으로 요약·분석하고, 창업자 관점, 회사 차원의 OKR, 주요 고객 성과, 핵심 전환 과제의 진행 상황과 도전 과제를 포함해 AI 및 클라우드 전략 관점에서 향후 방향성을 설명하시오.”실제 이해관계자에게 전달되는 결과물과 동일한 수준의 기타 임원 보고용 리포트
이 데이터셋에 대해 RACE 프레임워크를 적용해 모델이 생성한 리포트를 평가한 결과, Deep Research의 RACE 점수는 62.72점으로 나타났습니다.
RACE 기준에서 50점 이상은 인간이 작성한 기준 리포트보다 높은 품질을 의미하며, 이는 생성된 리포트가 해당 벤치마크에서 기존 인간 작성 리포트를 이미 상회하고 있음을 시사합니다.
공개 벤치마크와 엔터프라이즈 중심의 내부 벤치마크를 함께 활용함으로써, Deep Research의 평가 전략은 산업 표준 성능과 실제 업무 활용 품질을 동시에 검증하도록 설계되었습니다.
참조 기반 벤치마크 요약

II. Reference-Free 평가 전략
Side-by-Side 비교 평가
참조 기반 벤치마크 외에도, 경쟁사의 Deep Research 제품과 참조 없이(reference-free) 결과를 직접 비교하는 병렬 평가(side-by-side evaluation)를 함께 수행합니다.
각 리서치 과제에 대해 다음과 같은 방식으로 평가가 진행됩니다.
Deep Research를 사용해 리포트 생성
경쟁 제품(예: ChatGPT Deep Research)으로 동일 과제 리포트 생성
두 결과물을 LLM 판정자 기반 승 / 무 / 패(win / tie / lose) 프레임워크로 비교
이 방식은 사용자가 실제로 두 결과물을 나란히 비교해 선택하는 상황을 모사합니다.
이를 통해 단순 점수 비교가 아닌, 실제 선호도 관점에서의 품질 차이를 측정합니다.
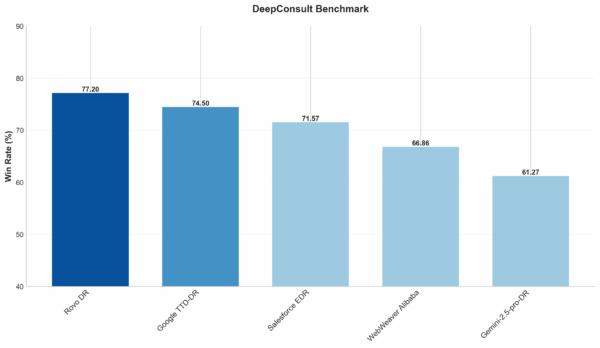
DeepConsult 평가
DeepConsult는 시장 분석, 투자 기회 평가, 산업 분석, 재무 모델링 및 평가, 기술 트렌드 분석, 전략적 비즈니스 기획 등 실제 컨설팅 업무에 가까운 과제를 폭넓게 포함한 데이터셋입니다.
주요 과제 유형
시장 분석
투자 기회 평가
산업 분석
재무 모델링 및 평가
기술 트렌드 분석
전략적 비즈니스 기획
이 데이터셋을 활용해 Deep Research와 ChatGPT Deep Research를 side-by-side 환경에서 직접 비교하고, LLM 판정자가 각 과제별로 더 우수한 결과물을 선택합니다.
품질 비교 요약
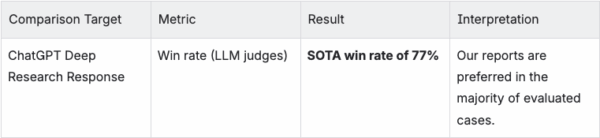
DeepConsult 기준 side-by-side 평가에서, Deep Research 리포트는 ChatGPT Deep Research 대비 77%의 승률을 기록했습니다.
이는 다수의 비교 상황에서 LLM 기반 판정자가 Deep Research의 결과물을 더 우수하다고 판단했음을 의미하며, 실제 의사결정 환경에서도 일관되게 높은 품질의 리포트가 제공되었음을 보여줍니다.
앞으로의 Deep Research
Deep Research v2는 완성이 아니라 새로운 기준선으로 제시됩니다.
실행 가능한 전문가 수준의 권고안 강화
단순한 정보 제공을 넘어, 트레이드오프를 명확히 제시하고 구체적인 선택지와 다음 단계를 드러내는 리포트를 지향합니다.사실 정확성과 인용 품질을 검증하는 가드레일 강화
핵심 주장과 출처 간의 연결성을 체계적으로 검증해, 근거가 부족한 응답보다 검증되고 인용이 명확한 결과를 우선합니다.ADF 기반 시각적 구조와 데이터 시각화 확대
Atlassian Document Format(ADF)과의 통합을 통해 시각적 구조를 강화하고, 데이터 분석 결과를 차트와 그래프로 표현해 인사이트를 더 쉽게 전달하도록 개선이 이어지고 있습니다.
Deep Research는 단순한 AI 기능을 넘어 팀의 사고와 의사결정을 확장하는 연구 파트너로 발전하고 있습니다.
참고 링크
How Rovo Deep Research works – Work Life by Atlassian How Rovo Deep Research works
Introducing Rovo Deep Research, grounded on your data – Work Life by Atlassian